株式会社はてなに入社しました
前回:
『好きな技術《コト》で、 生きていく技術』という題で話した。技術選択にどんな筋を通すか、技術選択というものを通じて職業人・趣味人としてどういう人生を送るか、という話。
YAPC::Kyoto 2023で聞いた![]() id:ar_tamaさんのあの日ハッカーに憧れた自分が、「ハッカーの呪縛」から解き放たれるまでというトークが良かったこと・それがYAPCのコミュニティに強く受け入れられたことに思うところがあり、今までしたことのない系統の話題を話してみようと思った。
id:ar_tamaさんのあの日ハッカーに憧れた自分が、「ハッカーの呪縛」から解き放たれるまでというトークが良かったこと・それがYAPCのコミュニティに強く受け入れられたことに思うところがあり、今までしたことのない系統の話題を話してみようと思った。
自分にとってとても挑戦的だったので![]() id:ar_tamaさんにお礼を言うことがYAPC::Hiroshima 2024の目的のひとつだったので、懇親会で無事に果たせてよかった。改めてこの場でもありがとうございます。
id:ar_tamaさんにお礼を言うことがYAPC::Hiroshima 2024の目的のひとつだったので、懇親会で無事に果たせてよかった。改めてこの場でもありがとうございます。
2つ前の同じ部屋で![]() id:Songmuさんの「Blogを作り、育み、慈しむ - Blog Hacks 2024」というトークでも、砂場としてのブログの良さの話が出てきてシナジーを感じたので咄嗟に資料に追記するなど、こういうライブ感がカンファレンスで話す醍醐味。
id:Songmuさんの「Blogを作り、育み、慈しむ - Blog Hacks 2024」というトークでも、砂場としてのブログの良さの話が出てきてシナジーを感じたので咄嗟に資料に追記するなど、こういうライブ感がカンファレンスで話す醍醐味。
what you likeというテーマからよく連想されるように、こういう技術選択に関する内容の応募は多く、正直落ちるだろうと思って慌てて別の内容でもうひとつプロポーザルを出したのだけれども、結果的にはこちらが採択された。
一際倍率の高い今回のYAPCの中でもこの手の話題のトークとして採択されたことをとても嬉しく思っているし、だからこそベストトーク賞をいただけなかったことがかなり悔しい。
これまで自分がカンファレンスに登壇する際は、基本的に作ったソフトウェアをひっさげて話すことばかりだった。その方が話しやすいというのはもちろんあるし、何より戦士たるもの拳のぶつかりあいですべてわかるみたいな気持ちもあった。
作ったモノがあると懇親会で「これうちでも欲しい」とか「こういう先行事例があるよ」といった話が聞けたり、後日実際に使われたりPRをもらったり……など題材としたソフトウェアで世界と繋がれる。だからトークそのものの反応というのは二の次で良いかと思っている。
一方、考え方を軸にしたトークが世界と繋がるには、聴衆の考え方・心を動かして大仰に言えば人生観を少しでも動かさなければいけないと考えている。
それを測るひとつの基準としてベストトーク賞が考えられるし、YAPCに参加して10年目だし、一度くらいはオーディエンスのことを目一杯意識したトークをしようと思い立った。
トークを良いかんじに組み立てるために![]() id:Soudaiさんに壁打ち相手になってもらい数ヶ月前から内容を練るなど、今まで体験したことのない取り組みができたのは良い経験になった。
id:Soudaiさんに壁打ち相手になってもらい数ヶ月前から内容を練るなど、今まで体験したことのない取り組みができたのは良い経験になった。
だからこそ受賞に至らなかったことはただ悔しい。でも![]() id:mitani49さんのVISAカードの裏側と “手が掛かる” 決済システムの育て方はおもしろかったしただただ納得。
id:mitani49さんのVISAカードの裏側と “手が掛かる” 決済システムの育て方はおもしろかったしただただ納得。
次までに刀を研いでおきます。
YAPC::Asia 2013 で『Vagrant と Chef で プログラマブルな 開発環境をつくる』話をした - Sexually Knowing
初めて参加した大きなカンファレンスがYAPC::Asia 2013で、初めて参加したYAPCも2013. つまり個人的にYAPC10年目ということになる。10年か……。
こういう思い入れもあり先述のように今回のトークには特別思うところがあったといえるかもしれない。
自分は首都圏に住んだことがないし、あまり人脈を広げるほうでもないので、こういうカンファレンスに参加する度に1人か2人は初対面の人が増えるので、10年以上こういうコミュニティに参加していても旧交の温めばかりになっていない。これってけっこうえらいのでは?
他に聞いたトークはいろいろあれど、とほほさんのキーノートはただただすごかった。まずけっこう80年代からゴリゴリにコンピュータと仕事しているという話がおもしろかったし、ちょくちょく挟まる話もいちいちインパクトが強かった。当時のUNIX向けにTCPスタックを実装したよ、とかさらりと触れられていたけれど、それひとつで余裕でトークになるのでは?
「どうして続けられるのか?」という問いに淡々と「好きだから続けられる」と答えていらっしゃったのが印象的で、言葉尻は飾っておらず平凡と言ってさえよいが、一連のトークを聞いたあとだと凄味すらあった。 これだけで広島に来てよかったと確信している。
薄々感付いていたけど、車に乗るようになってからパッキングが冴えなくなった。
具体的には今回、ダッフルバッグと会期中に使うバックパックとボディバッグを持っていったのだけれど、たとえば駐車場からホテルに移動する時にバッグが多くて大変だった。
公共交通機関を使う時は基本的にバックパックひとつで済むよう持っていくものを厳選したり工夫を凝らしていたけれど、なまじ荷物を運ぶ空間が贅沢になったせいで怠惰になっている。
たとえ車移動であってもパッキングを突き詰めれば、たとえば自転車を積んでいく余裕などが生まれて出先でできることも変わってくるのでここらで意識を改めたい。
懇親会などで自然とそういう話になったのだけれど、京都を出てどこかに移住しようと考えた時に最後まで金沢市と迷ったのが広島市だった。
それくらい好きな街で、やはり水に囲まれた街は良いですね。金沢より栄えていて、公式懇親会の後にN次会をやるぞとなった時になんだかんだ深夜にやっている飲み屋がそこそこ見つかるのはすごい。
車に乗るようになると、都市高速が走っているのはけっこう驚くというか、発展度合いとしてはけっこう上のほうなんだよなということを思い出す。 しかし自分は金沢くらいの静かさがちょうどいい。
あと愛車の里帰りでもあるので、マツダミュージアムを見学したかったのだけれど土日はやっておらず月曜日はとっくに埋まっていたのでチャンスはなかった。日曜日で本社も閉まっており聖地巡礼もできなかった。次回以降の宿題とします。
何かをやる上で失敗しないに越したことはないですし、そのリスクはあらかじめ減らせたり排除できると良いのはもちろんですが、どうしたってゼロにはできません。
それが新規事業のような不確実性の高い領域であればなおさらで、正解の見えない世界での判断は少なからず博打の性質を孕むことになります。
ソフトウェアエンジニアとしてそういった場面で判断をする時に、合理性で選択肢を減らしていった後で残った選択肢を選ぶ時の決め手として、自分は「失敗しても何を残せるか」という観点を持ち出します。
正解のない世界で自分を鼓舞するためのある種のまじないのようなものですが、これについて掘り下げてみます。
終わりを意識して始める: プロジェクトのプレモーテムを行う方法 [2022] • Asana
プレモーテム (premortem) とはプロジェクトの終了をまず予想し、そこから逆算してリスク要因を見つけたり必要な手順を発見する取り組みのことです。
これはポストモーテム (postmortem) という障害・事故の振り返りを指す言葉との対比として生まれました。
ポストモーテムは「検死」という意味で、そこから転じて障害や事故で生じた損害がいかにして起きたかを振り返るというアナロジーで使われだしました。
このアナロジーに無理矢理あてはめるなら、プレモーテムはさしづめ生前葬にあたるでしょう。
アジャイルサムライなどで取り上げられている「夜も眠れなくなる原因はなんだろう?」や「ご近所さんを探せ」はプレモーテムの一環といえます。
ポストモーテムの元々の意味を考えれば、事業を行う上での失敗は元の表現でいう死にあたります。
これは本当に会社の不可逆的な終わりを意味するかもしれませんし、事業やプロジェクトなどの継続可能性の否定にとどまるかもしれません。
いずれにせよ「死」を克服することはできないと考えるのが合理的です。
そうすると「死」がやってきた時に、我々は世界に何を残せたか・世界から何を受け取れたかが、事業やプロジェクトという「生」がどんなものだったかを表すことと言えるでしょう。
何も爪痕を残せなければただの徒労に思えるでしょうし、たとえ事業やプロジェクトの成功という天寿を全うできなくとも何か「これはやれた」「これは得られた」というものがあれば意義あるものだったと言えることでしょう。
組織に所属して事業やプロジェクトに貢献することを選ぶ従業員として、もちろん事業やプロジェクトの成功を第一に考えるべきですが、同じくらいSWEとして何を残せるか・何が得られるかも尊重すべき・されるべき点だと考えています。
たとえ事業やプロジェクトが成功を収められずとも、今後のサービス開発に活かせるものがひとつでも得られたのであれば、一連の過程に価値はあるといえるでしょう。
言い換えれば事業やプロジェクトの成功 だけ を追い求めた時、もし失敗すれば後には何も残らず、ただ関係者には徒労感と虚無だけが残るでしょう。
追うべきものはなんでもよくて、ポートフォリオに加えたいと思っていた言語や機能でもいいし、新しいリーダーの抜擢でもいいし、組織体制でもなんでもいい。
それは携わるリーダーが率先して考えるべきで、特に職能軸のリーダーがメンバーのキャリアを守る意味でもあらかじめ考えておくべきことでしょう。
事業軸と職能軸のマトリクス型組織をとる意義のひとつであるといってもいいです。
「何の成果もあげられませんでした!」を避けるために、事業やプロジェクトの成功の定義を0点 or 100点のall or nothingではなく、100点をとれなかった時でも30点や60点の成果を狙えるよう、30点や60点だった世界をあらかじめ想像・定義しようという話でした。
all or nothingの定義だと、やがて失敗のリスクが大きすぎることを嫌って大胆な判断ができなくなり「これくらいならいけるだろう」という50点くらいの成功を狙うようになります。
しかし失敗する可能性はゼロではないので、実際は0点 or 50点というハイリスク・ローリターンな判断をとることになり、けっきょく「成功」しても大きく進めない上に、相変わらず失敗したあとは焼け野原というジリ貧の状態に陥りやすくなります。
「身の丈にあった判断をする」ということは言い訳をする余地をなくすことでもあり、それによって先に精神的に追い詰められてしまい、ポテンシャルを十分に発揮できずに失敗に繋がる……ということもままあります。
何より成功しても失敗してもどっちに転んでもインパクトの小さいプロジェクトに関わりたいとは思いません。どうせやるならワクワクするほうがよいです。
もちろん大胆不敵と蛮勇は同じではありません。蛮勇かどうかを知るためには、自分の身の丈がどれくらいかを知っておかなければいけません。
だから日頃からナイフを研いでおくことが大事で、そのために使えるもの・時間はうまく使おうと心がけています。この前書いた記事もそういう取り組みの一環でした:
職業ソフトウェアエンジニアが普段の業務でソフトウェアを作る時は、過不足ないソフトウェア製作を通して試行錯誤を素早くこなして目的に至ることが求められているでしょう。
『リーン・スタートアップ』やアジャイル開発などで説かれている考え方です。
ソフトウェア産業が扱う領域がより高度で複雑になってきたために生じる不確実性とうまく付き合うためのやりかたで、今日では前提とされます。
一方で、それらを支えるソフトウェア技術の幅や深さを広げるためにはどうすれば良いか、必要性は理解されてはいても具体的な実現方法を模索しているという人が多いのではないでしょうか。
ここでは、会社としてどうするかという点から一旦離れ、一個人のソフトウェアエンジニアとしてどうするかという観点で考えをまとめたいと思います。
自分は「作りたがり」な性質で、業務では常にオーバーエンジニアリングに走ってより新しいこと・おもしろいことを試したい欲望と戦っています。
手札を増やすことは個人としてもひいては組織にとって良い影響があると信じていますが、そういったお題目より何より、単に「そうしたい」からそうしたいのだ、という欲望を抱えているだけなのだと思います。
特に新しく何かを立ち上げるとか、作って置き換えるという時は、格好の機会なのでなんとかして欲望を満たしたくなります。
同時に、そういった新しく立ち上げたり置き換えるという瞬間は、不確定要素が多く見通しが悪い瞬間ともいえ、作るモノの核から逸れた部分に時間を割いては後々に自分たちの首が絞まることもよくよく理解しています。
まず、自分(たち)にこうした欲望があるかもしれないことを自覚し、そしてそれをうまく飼い慣らしてよりクリアな思考で立ち向かわなければ誰も幸せになりません。
何かおもしろいことをやる・新しいことを試すことさえできればよく、その格好の機会が転がってくる場が業務であるというだけなので、業務以外に機会を求めることができれば葛藤せずに済みそうです。
その場として自分が気に入っているのが、タイトルにも挙げた趣味プログラミングです。
趣味プログラミングで作るモノを自分は 砂場プロダクト あるいは単に 砂場 と呼んでいます。
砂場では、自分の資源 (時間、お金、好奇心、etc.) が許す限り何をやっても良いし、何を選んでも良いです。つまり「作りたい」という欲望を存分に満たせます。
いつもと違うことをしてみたいと考えるものの、いざ自由を手にしたら何をどうしたら良いか悩んでしまうかもしれません。
自分が砂場で遊ぶ時に考える軸を以下にいくつか挙げてみます。Webアプリケーションエンジニアなので、Webサービスを主な題材として想定しますがWebサービスによらない軸だと思います。
ぱっと思いついて、実際に変えてみたことのある点だけでもこれくらいあります。
次に大切なのが 題材は同じままでも良い ということです。つまり同じ砂場プロダクトのまま、データストアを入れ替えてみてもいいし、IaCツールを変えてみてもいいです。
むしろ動いているものはそのままに一部だけ移行するということのほうが現実にはよくありますし、チュートリアルをやるだけでは得難い体験なので価値があります。
砂場でどう遊べば良いかはわかったけど、そもそも何を作ればいいか思いつかないよ、ということもあるかもしれません。むしろそういう悩みのほうが多いでしょうか。
「何を作ればいいか悩む」という声に自分はよくポートフォリオかブログを作ってみてはどうか、と答えます。
ポートフォリオとは自分の経歴とかプロフィールをまとめたもので、自分の場合だと https://aereal.org/ です。
ポートフォリオはページ数は知れているし、更新頻度もそんなに高くないので立ち上げ時の負担が少ない割に、落ちていると格好がつかないので死活監視や変更の滑らかな反映などを真面目に考えたくなります。
SLOを高めたいという内発的動機付けが強く働くともいえます。
ブログは、Webアプリケーションとして素朴ながら拡張しがいがあってネタに困りにくいです。
たとえば:
……などなどがあります。
ポートフォリオと同様に落ちていたらやはり気まずいのでちゃんとしようという気になりますし、そこそこ書いていれば検索エンジンクローラもやってくるので人間以外のトラフィックを扱う良い題材になります。
また、何かを試す時に都度新しく作らずとも、同じものを作り直してもよいです。これを 式年遷宮 と呼んでいます。
たとえば自分のポートフォリオは当初、GitHub Pagesでホストしていましたが内容や基本的な実装はそのままにFirebase Hostingに移行し、その後、フレームワークをNext.jsに変えたりなどしています。
ネタを見つけるのはやはり大変ですが、一度見つけたらちょっとずつ手を加えていけば飽きることはないでしょうし、自然と愛着が湧いて運用をしっかりしようという気持ちにもなれるはずです。
この記事では趣味プログラミングを通して、ソフトウェアエンジニアとしてのエゴとうまく付き合う方法について述べました。
しかし、あくまでこれは職業ソフトウェアエンジニア個人としての考え方を提示しただけで、組織がすべてのソフトウェアエンジニア従業員に強いるないし求めることは違うと考えています。
組織の観点ではあくまで、組織が提供するリソースにおいて従業員が然るべきスキルアップを図れるようになっているべきで、個人のプライベートな時間を費すことを求めるのは破綻しています。
それでも示唆は得られると思います。こういった考えや振る舞いを推奨したいのであれば、プログラミングをするだけの十分な余裕があることは必須です。
単純に残業時間が多くては物理的に確保できないでしょうし、普段の業務で心的な負担が強ければ、たとえ時間が余っていても余暇時間は疲れ切った内面を整えることに終始するほかないでしょう。
こうした考え方は特別新しいものではなく、古くはGoogleの20%ルールなどにあたることができます。
この記事はOpenTelemetry Advent Calendar 2023の4日目の記事です。
こんにちは・こんばんは・おはようございます、![]() id:aerealです。最近は所属組織のブログをよく書いています。
id:aerealです。最近は所属組織のブログをよく書いています。
2023年は個人的にOpenTelemetry元年を迎えたところ社会でも元年めいているようなので一緒に盛り上がるためにも、この記事では掲題の通りCollectorをカスタマイズするテクニックについて紹介したいと思います。
confmapとはOpenTelemetry Collectorの設定ファイルを解決して決定的な値を作るためのパッケージです。
confmap providerとは設定ファイル中の ${env:DD_API_KEY} のような記述を解決するコンポーネントで、外部のデータソースから値を取得します。
秘匿情報やデプロイごとに動的に変えたい値を指定したい時にこのコンポーネントを使うことで、設定ファイルはそのままにCollectorの挙動を変えられます。
たとえば設定ファイル中の ${env:DD_API_KEY} のように記述すると環境変数の DD_API_KEY を参照できます。
Collectorのcoreには環境変数の他、ファイルやHTTP/HTTPSエンドポイントと通信するconfmap providerが含まれています。
しかし商用環境でアプリケーションを動かすシーンでは十分とはいえず、たとえば秘匿情報はふつう専用のサービスに保存し、実行時に都度取得するでしょう。 たとえばAWSであればSSM Parameters StoreやSecrets Managerが挙げられます。
当然、サービスに認証情報を渡す必要があり、認証情報をキャリーする場所はHTTPヘッダが普通なので、httpsproviderではやはり実用上十分とはいえません。
そこでconfmap providerを自作し、それを組み込んだOpenTelemetry Collectorをビルドし動かす手があります。 なおOpenTelemetry Collectorを自前でビルドする際の知見は筆者が所属組織の開発者ブログで書いた記事も参照してください: refs. Lambda Extensionと自家版OpenTelemetry Collector - Classi開発者ブログ
confmap providerを自作するにはconfmap.Providerインターフェースを実装する型をConfiProviderSetings.ResolverSettings.Providersに渡します。 refs. opentelemetry-lambda/collector/internal/collector/collector.go at own-dist · aereal/opentelemetry-lambda · GitHub
confmap.Providerは Retrieve() で仕事を果たします。引数に渡される uri はたとえば ${awsssm:/path/to/param} という記述であれば /path/to/param という文字列が入ります。
Retrieve() は、この引数を外部サービスなりに渡して得たデータをconfmap.Retrievedという型で包んで返す責務があります。
confmap.Retrieved はすべてのフィールドがプライベートなので confmap.NewRetrieved() 関数のみで作れる構造体です。
ドキュメントにあるようにおおむねJSONやYAMLと相互に変換可能な型のみを渡せますが、marshal/unmarshalをカスタマイズする方法は少なくとも公開インターフェースとして現在提供されていないようですので、NewRetrieved()が許容する型をその通りに返さなければいけません。
以上を踏まえてAWS SSM Parameters Storeからパラメータを取得するconfmap providerを実装したコードが以下になります: otel-confmap-provider-awsssm/provider.go at main · aereal/otel-confmap-provider-awsssm · GitHub
AWS SDK Go v2を使ってssm:GetParameterを呼び、その結果を素朴にconfmap.NewRetrieved()に渡すだけです。
SSMとの認証はAWS SDKのデフォルトの認証情報チェーンに頼っています。即ちAWS環境ではメタデータエンドポイントを介して得られたトークンを使います。
ローカルなどその他の環境で動作させるには AWS_ACCESS_KEY_ID などの環境変数を設定するか ~/.aws/credentials に適切な値を置く必要がありますが本題から逸れるのでここでは詳しく触れません。
言い換えれば自作したconfmap providerで外部サービスへ認証するには環境変数などconfmap providerに頼らない方法で認証情報を得る必要があります。
また筆者が実装したParameters Storeから取得するconfmap providerは都度HTTPリクエストを投げればよいので使っていませんが、confmap providerが終了した際に呼ばれるイベントハンドラを設定することもできます。
つまりデーモンのように振る舞うconfmap providerを実装することができます。これはステートフルな通信プロトコルを使うことを示すだけではなく、設定のホットスワップに対応する意欲があればサポートできることも意味します (実際に変更を検知するコールバックにアクセスできます)。
以上の解説は公開されたインターフェースとドキュメントコメントによるものですが、confmapパッケージのドキュメント自体はWIPであると書かれているので、実装から離れた設計や思想の部分は誤解などがあるかもしれません。
現在のところconfmap providerはcontrib系リポジトリを含めても素朴なものしか見当たらないので、実際にWatcherFuncなどをどのように活用するべきなのか筆者も理解しかねています。
この記事がconfmap providerやOpenTelemetry Collectorの理解の一助になったり、自作してみるきっかけになれば嬉しいです。
良き監視ライフを!
そういう話をします。
職業SWEなので仕事での経験ももちろん話しますが、同時に趣味SWEでもあるので仕事の時間と趣味の時間を最大限効率的に使ってより楽しくいろんな技術に触れて楽しく暮らしたらどうしたらいいんだろうね? 的な話になる予定です。
ざっくりいうとキャリア形成的な内容になるのかもしれませんが、個人的に自分自身がそういうキャリアとか人生観みたいなふわふわした話を壇上からすることに抵抗があるので、できるだけ作ったもの・やったことをベースに多くの人が感じている・感じてきた不安や悩みを掘り下げる一助になったらいいね、という気持ちで準備しようと思います。
qron: Cloud Native Cron Alternativeの今
掲題の通りのトークをした。元々YAPC::Kyoto 2020のトークとして採択されていたトピックを2023年版として話すことに。
オンサイトのカンファレンスに参加するのは2019年のbuilderscon以来なので2年半ぶりくらい。
#builderscon tokyo 2019で「自動作曲入門」について話した - Sexually Knowing
もともとあったアイデアを必要に駆られて仕事で作ったものの話。
2020年当時はできたてほやほやだったけど2023年はもう運用して数年が経とうとしているので「実際動かしてみてこうだったよ」という話も盛り込んだ。
結果として強気の40分枠で応募し、採択の運びとなった。自分で選んでおいてだけど40分のトークを黙って聞いているのはけっこう気合がいるので構成とか話し方とかに気を遣う。
最近は別のプロジェクトで絶賛がつがつ作っているところであるものの、ずっと世に出ていないしプロジェクトやチームはどんどん勝手にめちゃくちゃになっていくしで気が滅入っていたけど、感想ツイートとかでおもしろそうって言われているのを見ると自分の仕事がちゃんと見られた気がして嬉しかった。
あと質疑コーナー含めて突っ込んだやりとりができたのも良かった。ソフトウェアエンジニアとして生きているっていう実感がそこにある。
はてなにいた頃ずっとお世話になっていた ![]() id:onishi さんではあるけれど、キーノートに登場するエピソードは以前に聞いたことはあってもその当時にどんな思いを抱いていたかといったことは意外と聞いたことがなくて「そういうことがあったんだ」という新鮮な驚きと共に、onishiさんのパーソナリティ・考え方の裏付けがとれたような気がして得心がいった。
id:onishi さんではあるけれど、キーノートに登場するエピソードは以前に聞いたことはあってもその当時にどんな思いを抱いていたかといったことは意外と聞いたことがなくて「そういうことがあったんだ」という新鮮な驚きと共に、onishiさんのパーソナリティ・考え方の裏付けがとれたような気がして得心がいった。
onishiさんもnekokakさんも「やるべきことをやってくれる誰かを待つのではなく自分がやる」というようなことをトークで話していて、やっぱり手を動かした人だけが世界を変えるなんだなあ。
onishiさんはご自身をモブと謙遜・自虐されていたけれど、Web業界で花形とされているソフトウェアエンジニアの第一線とは少し距離があった・退いたというようなご自身の認識からしたらそういう表現は確かに的を射ていると評することもできるかもしれないと思う一方で「主人公」という生き方だけにこだわっていては果たし難かった功績を積み上げられてきたと思う。
前述の通りオンサイトのイベントは2年半ぶり。
もはやPerlを書いていないどころかエコシステムから遠ざかってからだいぶ経つけれど、YAPCに参加するタイプの人たちとはウマが合うなあと思った。
久しぶりに会う人・初めて会う人などなどと話しているうちに生粋のエンジニアとしての自分でいられているなあと感じてのびのびできた。
しかし2年半ぶりということで社交筋 *1 ががっつり落ちていて、日曜の夜にあったスピーカーディナーでは抜け殻になってただ蒸しカキを食べていた。
メンタルはともかくフィジカルの衰えも強く感じたのですぐに鍛えられるフィジカルは次に向けて鍛えておこう……。
仕事もプライベートも最近めちゃくちゃで果たして楽しめるのか不安だったけれど前日と併せて2日間楽しく過ごせた。
けっこうな数が知り合いが運営に関わっていることを知ってちょっと驚いたりもした。カンファレンスの運営ってものすごく大変と伺っているので。
よりカンファレンス運営が身近になったなと思う一方で、カンファレンスで日頃磨いてきた芸を披露することに改めてこだわりたいなという思いを改めた。 (別にスタッフになることと相反しないが……)
あらためてYAPC::Kyoto 2023開催おつかれさまでした、たのしかったです。
*1:社交するための筋肉
元々YAPC::Kyoto 2020に応募していた「qron: Cloud Native Cron Alternativeの今」をベースにした話をする予定です。
2020年当時は運用を始めたてだったので「こういうコンセプトで作ったやで」っていう話を中心にするつもりだったのですが、2023年現在は運用して数年が経ったこともあってコンセプトの紹介に加え「実際こういうところがうまくいっている・うまくいっていない」という話をしたほうが現実味があってよさそうだなと思い、タイトルも「〜の今」としました。
久しぶりにオンサイト開催されるカンファレンスで喋れるということでワクワクしています。個人的には初春の京都に出かける口実ができたのも嬉しいですし、登壇予定の面々の中に見知った名前もあったので久しぶりに顔を合わせられること・カンファレンスの発表を通して知見や交流を深める機会がまた巡ってきたことも楽しみです。
開催日の3/17は日曜日で次の3/19が春分の日であるため、連休チャンスと見なされ既に宿は混み合っているそうです。自分含めて遠方から参加される方々は早速宿を取るのが良いでしょうね。 迷ったら予約、チケット購入が吉と今年のおみくじも言っていました、間違いありません。
ちなみにチケット販売は2023/1/31までです (refs. 【販売期間は2023年1月31日まで】 YAPC::Kyoto 2023 参加チケットの販売を開始します! - YAPC::Japan 運営ブログ)。墓地が無料の時代は終わった、生きて今すぐチケットを買おう!!!
他、ちょくちょく使っているライブラリに軽微なバグ修正の報告をしたりPRをしたり、などなど。
hoist-gql-errorsは最近仕事で必要に駆られて書いたんだけど、Datadog APMの仕様に詳しくなったのでそのうち改めてまとめておきたい。
サラリーマンをやっている以上仕方ないのかもしれないが自分の思うようなことがやれなくてフラストレーションを感じ続けた1年だった。
別にそんなに独り善がりなことを考えているわけではないとは思っていて「組織が良い方向に向かうにはこういうことをやったほうが良いと思うし自分もやりたいからやらせてくれ」っていうような話で、マネージャーにも了承してもらえていたけれどやんごとなき事情でそれより優先してやらないといけないことが出てきて……みたいなかんじ。
で、その「やらないといけないこと」というのが有り体に言って楽しくない。
別に労働ってそんなもんでしょと言われたらそうかもしれないけれど、フルタイム労働者だったら1日の1/3の時間を捧げるわけで、週5日勤務だったら1年の1/4になる。 1年の1/4の時間をかけるならどうせなら楽しくてやりがいのあるものであってほしい。
もちろんフルタイムの労働をやめるという方向性も考えられるけれど、2つの点から直近ではあまり考えていない。
1つは収入の安定性の面。車を買って趣味になったので安定して (継続して) 今以上の水準の収入がほしいし必須だということ。
もう1つは感情的な話で、やっぱり事業会社の事業に継続して携わることで領域を問わずいろいろやれるのは自分の性格に合っている。 いろいろ関わることで苦しいところもあるけれど「ここが良くなればサービスの質が上がってユーザもハッピーになれるのに」というところが見える場面はどこにいてもあると思っていて、そういう時に自分の管掌外だからといって見てみぬ振りをするのは性格上、おそらくとても難しい。
けっきょく無視することで別のストレスを感じてしまうなら、自分の仕事の範囲を変に決めきらずにおいておきたい。
というところで年明けのYAPC Kyoto 2023でなにか話したいけれど、何を話そうか……と悶々としている2022年でした。
以下は過去の社内LT大会で発表した時の資料です。
友人とOKRの話になって思い出したので発掘しました。
趣味にOKRを取り入れてみた感想としては、とても遠い・あるいは抽象的なゴールに向かう際に「まず何をやればいいんだろう」と道筋を立てるためのフレームワークであり、またゴールにどれだけ近付けたかを観測するためのフレームワークでもある、というものです。
Objectiveがゴールで、Key resultsがパンくずのようなイメージを持っています。Key resultsを達成できたかどうかはパンくずを拾ったかどうかといえるでしょう。
目標は、場合によっては若干気後れするくらいの高いレベルに設定します。 成果指標は、数値化して測定し、簡単に評価できるようにします(Google では 0~1.0 の範囲で設定しています)。
from https://rework.withgoogle.com/jp/guides/set-goals-with-okrs/steps/introduction/

Goで書いたアプリケーションをリリースする際にやらないといけないことはいろいろある。
まず当然のこととしてコンパイルして成果物を作り、それをリリースする。 せっかくクロスビルドが容易なGoを使うので配布する成果物も可能な限り幅広い環境に対応させたい。
また、リリースに含まれる変更の概要をまとめたいわゆるChangelogのようなものも簡単に作れるとなおよい。
GitHubでホストするリポジトリのリリースについて主に考えたいので、リリースのホスティングはGitHubのReleasesになる。 各Releaseの説明をChangelogとし、変更がもたらされたPull Requestのリンクも添えたい。
リリースするということは新しいバージョンを決めて、Gitのタグを打つ必要もある。
ひとつひとつはよくある作業だし特段難しいことはないが、いちいち手でやっていられないのでCIに任せたい。 掲題の通りGitHub Actionsでこれら一連の作業を自動化させるという話。
GitHub Actionsによるリリース自動化それ自体は目新しいトピックではない。しかしこの記事で紹介するワークフローはgit pushする以外に開発者がとるべきアクションはない。 具体的には、世の中の先行事例はGitのタグ発行は開発者の手作業で、それを契機にパイプラインを開始する……というものばかりだがそれも不要になる。
最近はgoreleaserというツールがよく使われているのでビルドまわりはこれに任せる。
goreleaserには:
……という2点を任せる。
アップロード対象のリリースは実行したリポジトリに存在する最新のタグから同定される。 言い換えるとタグを打つのはgoreleaserの責務外となる。
[semantic-releaser][]というツールがある。JavaScript (Node) で実装されたCLIツールでConventional Commitsに従ってコミットログを書いておくとよしなに次のリリースバージョンを決めてくれる。
Conventional CommitsはSemantic Versioningを参照し、たとえば feat: blah blah ... とか書くと新機能の追加なのでminorの更新を含意する、などのルールを定義している。
Conventional Commitsに従うとコミットログから次のバージョンを決めるルールがツールを越えて相互運用できる。
他にもプラグインでGitHub Releasesを作ったりGitタグを打ったり、あるいはNPMにアップロードするなどができる。
JavaScriptで書かれていることからもわかるように元々NPMパッケージのリリースを主眼に置いてエコシステムが整えられたツールだが、前述のようにリリースバージョンの決定以外はプラグインとして実装されているので、NPMパッケージのリリース以外にも使える。 必要なのはConventional Commitsに従ってコミットすることだけ。
つまり semantic-releaseを使ってGitタグの発行を含むバージョンアップ作業を自動化し、発行された新しいタグに成果物を作成・紐付ける作業をgoreleaserで自動化する というのがワークフローのあらましになる。
実際のワークフローを例に説明する。
pkgboundaries/ci.yml at main · aereal/pkgboundaries
上記ファイルから抜粋・簡略化したYAMLが以下。
determine_release: runs-on: ubuntu-latest if: github.ref == 'refs/heads/main' outputs: will_release: ${{ steps.determine_release.outputs.new_release_published }} steps: - uses: actions/checkout@v3 - id: determine_release uses: cycjimmy/semantic-release-action@v3.0.0 with: dry_run: true env: GITHUB_TOKEN: ${{ github.token }} release: runs-on: ubuntu-latest needs: # - test - determine_release if: ${{ needs.determine_release.outputs.will_release }} steps: - uses: actions/checkout@v3 with: fetch-depth: 0 - uses: cycjimmy/semantic-release-action@v3.0.0 env: GITHUB_TOKEN: ${{ github.token }} - uses: actions/setup-go@v3 with: go-version: '1.18.x' - uses: actions/cache@v3 with: path: ~/go/pkg/mod key: go-${{ hashFiles('**/go.sum') }} restore-keys: | go- - uses: goreleaser/goreleaser-action@v2.9.1 with: version: latest args: release --rm-dist env: GITHUB_TOKEN: ${{ github.token }}
determine_releaseとreleaseという2つのジョブに分けている。
determine_releaseは次のリリース予定を調べるジョブで「実行時点で新しいバージョンが発行されそうか」を示す真偽値 will_release を出力する。
cycjimmy/semantic-release-actionというsemantic-releaseを実行するActionがあり、その outputs.new_release_published という真偽値を参照している。
determine_releaseでは dry_run: true を指定し実際のリリースは行わず、バージョンアップ予定だけを調べる。
releaseジョブは実際にリリースを行う。
まず needs にdetermine_releaseを指定する。これは単に依存関係を宣言することに加えて needs コンテキスト経由でdetermine_releaseジョブの出力にアクセスする目的もある。
if: ${{ needs.determine_release.outputs.will_release }} で「 needs.determine_release.outputs.will_release がtrueだったらreleaseジョブを実行する」という意味になる。
新しいバージョンアップを要する変更がコミットされていなければリリース作業は行われない。
参考: - Workflow syntax for GitHub Actions - GitHub Docs - Contexts - GitHub Docs
続いてsemantic-releaseを実行し、GitHub Releasesを作る。 以下にsemantic-releaseの設定を引用する:
{ "branches": [ "main" ], "plugins": [ "@semantic-release/commit-analyzer", "@semantic-release/release-notes-generator", "@semantic-release/github" ] }
from pkgboundaries/.releaserc.json at 8f58c3dd5880534c1fd8cc8f513795722b52b279 · aereal/pkgboundaries
特別な設定は必要としない。デフォルトでNPMパッケージを公開する @semantic-release/npm が有効になっているのでそれ以外の有用なプラグインだけを明示しているだけに留まる。
最後にgoreleaserを実行する。 goreleaser-actionというインストールから実行までをよしなにやってくれるActionがあるのでこれを使う。 goreleaser/goreleaser-action: GitHub Action for GoReleaser
goreleaserはYAMLでいろいろ挙動をカスタマイズできるのだが、今回重要なのは release.mode になる。
release: mode: keep-existing
from pkgboundaries/.goreleaser.yml at 8f58c3dd5880534c1fd8cc8f513795722b52b279 · aereal/pkgboundaries
goreleaserもリリースノートの作成やGitHub Releasesの作成ができるが、今回のワークフローではそれらはsemantic-releaseに任せている。
mode: keep-existing を選ぶとタグに対応するGitHub Releasesが既に存在したらタイトルや本文を置き換えず成果物だけアップロードするという挙動になる。
こうすることでsemantic-releaseとうまく共存できる。
リリース時に人間による確認を挟みたいという場合には、Environmentsが使えるかもしれない。
参考: Using environments for deployment - GitHub Docs
EnvironmentsはDeploymentsに関連する概念で、その名の通りデプロイ対象の環境を表す。 Environmentsはそれぞれデプロイ時に必須となるcommit statusやレビュアーを指定できる。 これら機能はBranch protection rulesと似ていて、たとえばproduction環境では所定のチームやユーザのレビューなしにデプロイできない、といった設定ができる。
参考:
GitHubにおけるDeploymentsは単にイベント履歴とそれらに応じたWebhookでしかない。
最近追加されたGitHub Actionsとの統合では、ジョブに environment: production のように記述することである環境の利用を宣言できる。
このジョブ実行開始時にDeployments APIでdeploymentとdeployment_statusが作成される。完了するとsuccessもしくはfailureの記録がGitHub Actionsによって行われる。
実際のデプロイ処理はジョブのstepとして自由に定義できるので、この記事で紹介したワークフローをデプロイ処理として記述することもできる。
するとEnvironmentsの機能でDeploymentsの開始時にチーム・ユーザによる確認を挟んだ上でリリースする、といったことが実現できる。
これは規模の大きいチームで厳格な統制を図りたい時に便利かもしれない。
仕事でお世話になっているkayac/ecspressoの機能の中にローカルのタスク・サービス定義と現在使われている定義を比較して差分を出力してくれるものがある。
これから加えようとしている差分をプレビューできるだけではなく、たとえばデプロイしようとしているわけでもないのに差分があればローカルの定義が古びていることがわかるのでCIに組み込めると便利。
しかし実際に使おうとすると困る点が見つかった。
たとえばタスク定義にイメージタグを書く際に {{ must_env 'IMAGE_TAG' }} のように環境変数を参照している時に「イメージタグ 以外 に差分がない」ことを確認するのが難しいということ。
理想的には image を無視したJSONの構造を比較して差分が出せると良い。あるいは出力されるdiffをパースして image の差分は無視するとかが考えられる。
が、いずれもecspressoの機能とするにはだいぶ領分を外れているので、Pull Requestを送ろうにもましな実装が思いつかないのでどうしたものか。
ECSのタスク・サービス定義に限った問題ではなくJSONのdiffを取る時に一部構造を無視できれば良いので、JSONの差分を取るライブラリを作ることにした。 それがaereal/jsondiffになる。
ドキュメントのExampleを見てもらうとわかりやすい。
jsondiff.Ignore(query /* gojq.*Query: ".a" */) みたいに使う。
無視するJSON構造はgojqのクエリが使える。
gojqは![]() id:itchynyさんによるjqのGo実装で、CLIコマンドだけではなくライブラリとしても使える。
id:itchynyさんによるjqのGo実装で、CLIコマンドだけではなくライブラリとしても使える。
他にJSONの構造を指定するクエリ言語のようなものというとJSON Pathが考えられたが、自分が普段JSONの構造を走査する用途ではjq (gojq) を使っているしライブラリ実装を提供していることを知っていたのでgojqを選んだ。
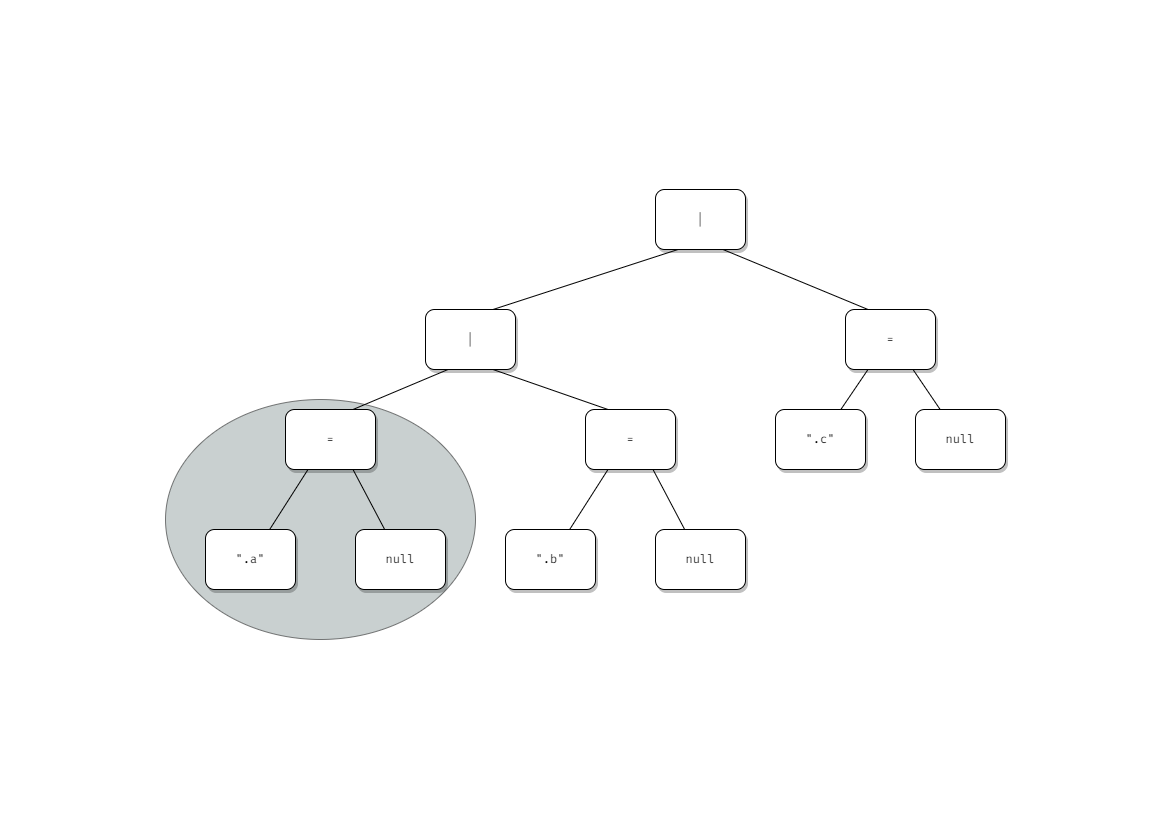
.a, .b, .c みたいなクエリを .a = null | .b = null | .c = null のようなクエリに変換し、これを実行した結果を比較することで特定のキーを無視する機能を実現している。
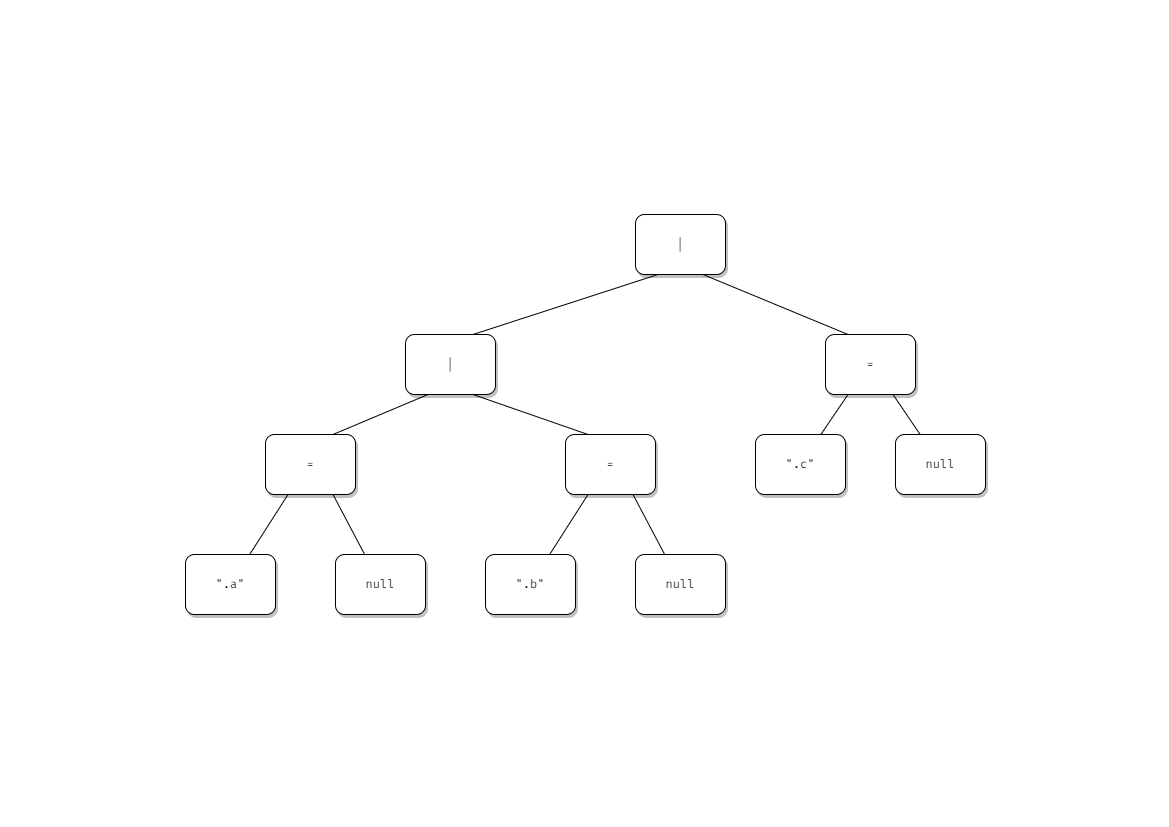
元となる .a, .b, .c というクエリの構文木は以下のようになっている。

これを変換して .a = null | .b = null | .c = null というクエリにしたい。構文木としては以下の通り。
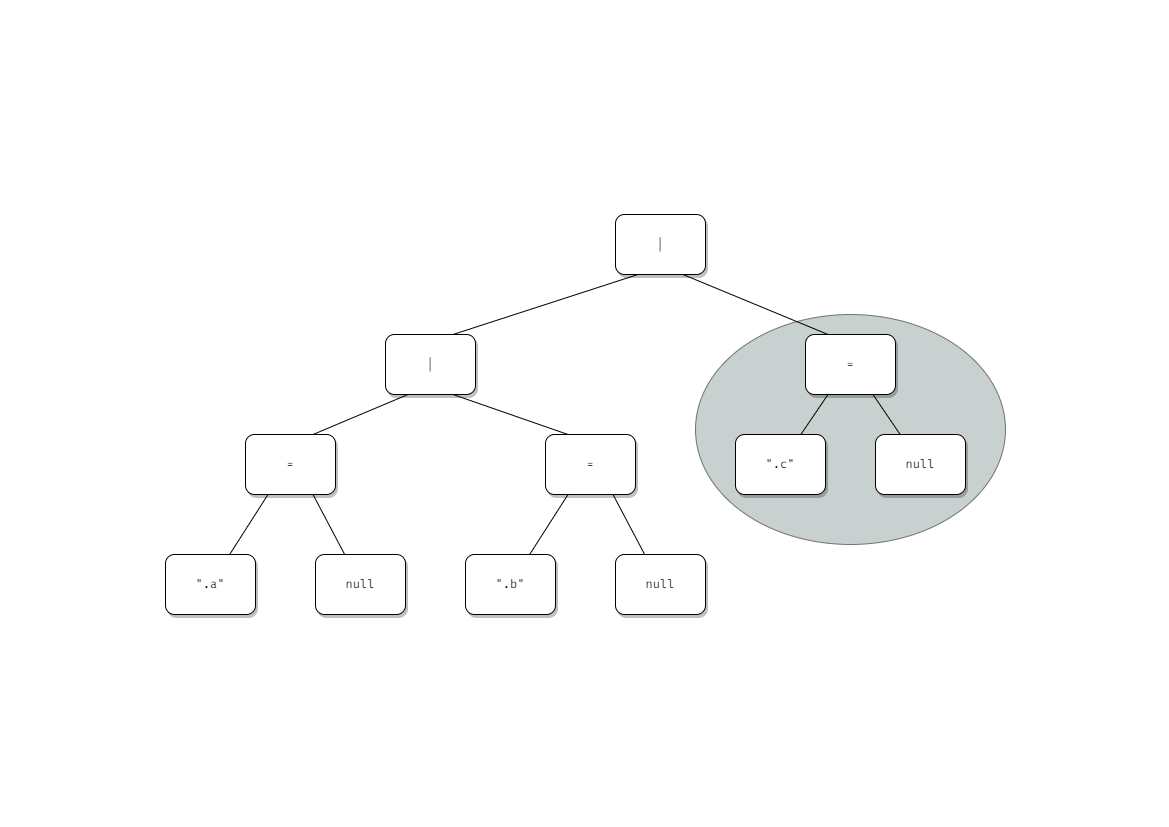
この木を作るには右端から作り、最後に処理したノードの左辺を更新していくのが合理的。
リストの右から処理していくといえばfoldRightである。しかしGoにそんな高級な関数はないのでfor文でデクリメントしていく実装になった。
see jsondiff/diff.go at 7e60f563b3601f48e6d4bf8c43210e4ac4614087 · aereal/jsondiff · GitHub
これを可視化すると以下のようになる。
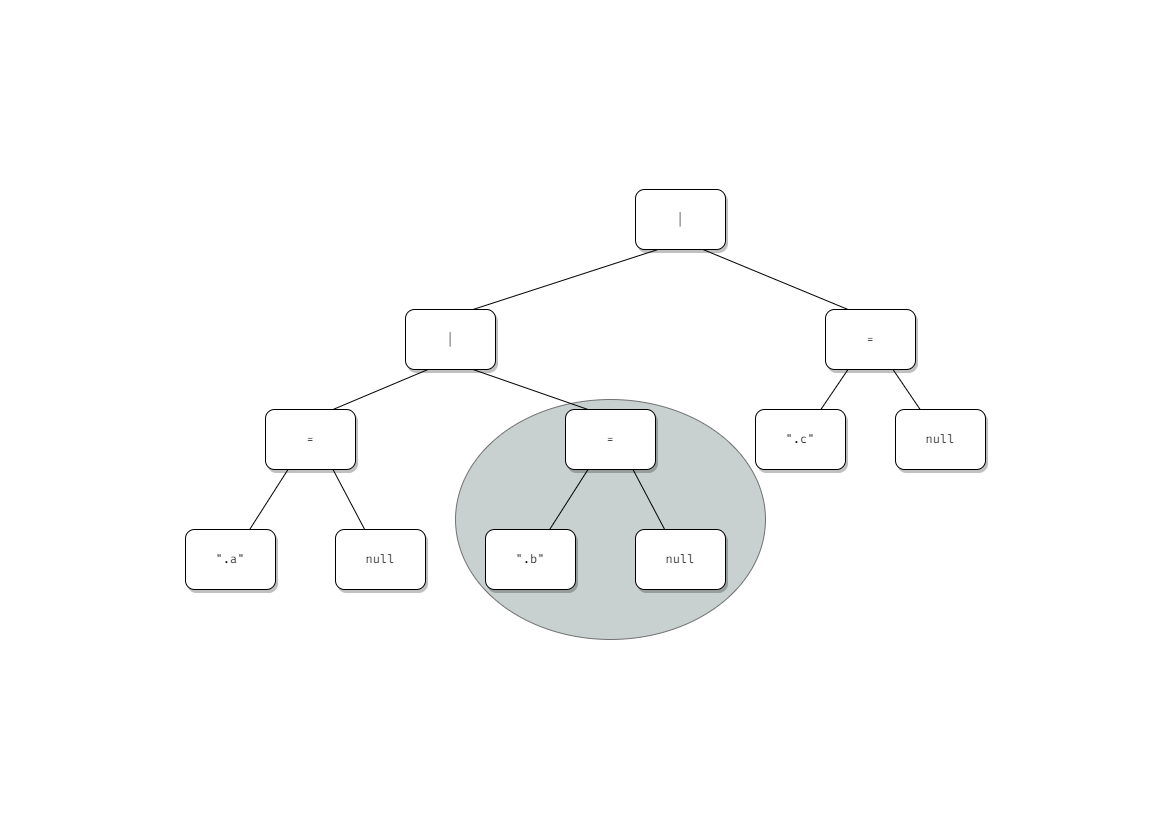
こう淡々と書くと「ふーん」という感じだけれど、 len(xs) - 1 から開始してデクリメントしていけば末尾からイテレートできることに気がついた時はちょっと気持ち良くなれた。
当初欲しいと思えたものが作れて満足。
これをecspressoやlambrollに入れるかというと、どうしようかなと思っている。
というのもCLIコマンドも作ったので、 ecspresso render させてそれを比較させるのでも良いのではと思っている。
いずれにせよライブラリとCLIコマンドの両方を作っておくことで、外部からも単体でも利用しやすくなるというのはgojqのお世話になって実感したので良い物作りができた。
色んなチームにヘルプで入ってプロジェクトやチームを良い感じにする手伝いをすることが主で、他に基盤サービスを作って運用したり、あとは開発者ブログ編集部をやったりなどなど。
現職での1年半くらいのキャリアにおいてソフトウェアエンジニアリングは高々3割くらいで、あとはプロジェクトやピープルをマネジメントするような仕事が占めていた。
前職でもWevoxを使っていて、その当時から振り返ってもありえないくらい低い「自己成長」スコアがここ最近ついていてクソワロタ (真顔) 状態だった。
このままだと退職 or dieしかないと感じたので、上司には「もうしばらくプロジェクトマネジメントはやりたくないでござる 絶対にやりたくないでござる」と上申して新しいチームへの配属を希望した。そしてそれは叶えられた。
Webサービスを作って届ける過程でプロジェクトやピープルをマネジメントすることの必要性は理解しているし、特に 今の 現職がそれら領域への梃入れを求めていることも理解している。
それでも 自分が やりたくないとは感じていたものの、義務感が勝っていたので受け入れていたが、我慢できなくなったという次第。
まずもって自分は人間を取り扱うのがとても苦手で、平均程度にはできるとは思うものの心的負担がめちゃくちゃ高い。
また自分はソフトウェア構築の道を究めたいと考えており、プロジェクト・ピープルマネジメントは近接する分野であるがそのものではない。 このため有限の時間を使いたい分野に割けていない状況に強いストレスを感じており、それがWevoxのスコアにも表れていたということだろう。
ソフトウェア構築のエキスパートとありたいのであって、プロ労働者になるつもりもなったつもりもない。 仕事は選びたいし仕事を選べる立場でありたいと思うし、自分がやりたくないことをやっているがためにこんな損失がありますよという主張に説得力を持たせるだけのスキルを備えておきたいと考えている。
そういうありかたを望んでいる自分にとってスキルを研鑽できない状態に陥ることは、まったく大仰ではなく自身の人生が破壊されることと同義である。
掲題の通りソフトウェアエンジニアリングですべての障害を破壊していきたい。
「運用でカバー」に相当する作業を自分から徹底的に排除していきたい。 結果的にそうなるとしても、まずソフトウェアエンジニアリングで解決できないか問いたいし、それを端から諦めるのはエキスパートとしての怠慢だと叱咤する。
これがDigital Transformationや!!!! というのを見せ付けていきたい。
そういえば5年くらい前にも似たようなこと書いていたなあと思い出したので置いておく: 「ついカッとなって……」取り組んだ 開発者のための開発 で業務効率を改善させた話 - エンジニアHub|Webエンジニアのキャリアを考える!
以上の文章は社内esaに書いた文章を加筆修正しました。
定期的にプロ労働者になりたくないと言っているなと気付いたのでその再確認。