Go でテキスト処理をする練習のために書いてみた。
mdtoc - The markdown ToC generator - ウェブログ - Hail2u.net が元ネタで再実装というかんじ。
小難しいことをやるとどうしても泥臭くなるけど、普段書いている高水準なコードはこれくらい泥臭くてともすれば効率が悪いんだろうな〜、ということを Go を書くたびに思っている気がする。
Go でテキスト処理をする練習のために書いてみた。
mdtoc - The markdown ToC generator - ウェブログ - Hail2u.net が元ネタで再実装というかんじ。
小難しいことをやるとどうしても泥臭くなるけど、普段書いている高水準なコードはこれくらい泥臭くてともすれば効率が悪いんだろうな〜、ということを Go を書くたびに思っている気がする。
社内 LT 大会で「数字で振り返る2016年」と題していろいろ個人にまつわる数字を集めたので整えたものを遅ればせながら旧年の振り返りとします。
| 年 | 金額 | 前年比 |
|---|---|---|
| 2016 | 389,277 円 | (124.54%) |
| 2015 | 312,547 円 | (136.27%) |
| 2014 | 229,352 円 | - |
カメラやレンズなどは含んでいない。主に Kindle 本や生活用品など。
年間でサラリーマンの月収として現実味のある額 *1 ほどしか使っていないと考えるかどうか。
この調子でいくと来年は45万くらい年間で使う目測だけど、そんなに成長するかな、どうかな。生活用品に使う額は減りはしないだろうけど大きく増えもしないだろう。
額の増加が鈍化すると踏んで特に考えないことにする。増加率が130%に戻ったら考える。
| 年 | 記事数 | 前年比 |
|---|---|---|
| 2016 | 73 | 486.7% |
| 2015 | 15 | 13.0% |
| 2014 | 115 | - |
2015年はロードバイクにはまったこと、小指を骨折したことが重なって激減したという背景がある。
そう考えると2016年はロードバイクにあまり乗らず PENTAX K-1 など大きな買い物をした割には2014年の6割程度で奮わない。
写真ブログは自分が発表するに耐えると考えたものだけを載せる方針なので、目が肥えてハードルが高まったかもしれない。
また、最近は組写真っぽいアプローチについて考えはじめて、1記事で複数の写真を載せることが増えたように思うので、1記事1写真が多かった気がする2014年と比べて写真数では見劣りしないかもしれない。
とにかくアウトプットの機会を増やさないことには上達しないし、気が向いたときに載せるくらいのペースだと選りすぐりを発表する場としても片手落ちなので、今年は数を重視して2014年の1.5倍まで戻したい。
| 機種 | 枚数 | 割合 | 採用率 |
|---|---|---|---|
| all | 4,925 | - | 17.6% |
| K-1 | 3,642 | 73.9% | 19.7% |
| K-3 | 1,202 | 24.4% | 11.6% |
| K-7 | 33 | 0.7% | 36.4% |
| dp0 | 48 | 1.0% | - |
Lightroom より。これを算出したのは12月2日だったので、実際はこれより増えている。
採用率というのは Lightroom でフラグを立てて現像し Google Photos に上げた写真の数の割合。20%弱という微妙な数字が素人っぽい。
意外とK-3が多かったなという印象だけれど3月から4月の梅・桜シーズンにまだいたのでさもありなん。
| 機種 | 枚数 | 割合 | 採用率 |
|---|---|---|---|
| all | 4,925 | - | 17.6% |
| 70-200mm | 231 | 4.7% | 12.6% |
| 35mm | 89 | 1.8% | 23.6% |
| 55mm | 785 | 15.9% | 13.9% |
| 31mm | 2,557 | 51.9% | 17.9% |
| 77mm | 886 | 18.0% | 20.1% |
こちらも Lightroom より。
31mm が大好きなことが使用率からわかる。一方で採用率は目立って高くないので、いいレンズだし気に入っているけれど、あとから自分の眼鏡に敵う写真が量産できているわけではない。
77mm は少し採用率が高いようにも見えるけど有意差はない。
| 年 | 実績 | 前年比 |
|---|---|---|
| 2016 | 226.6km | 19.93% |
| 2015 | 1,136.8km | - |
| 年 | 実績 | 前年比 |
|---|---|---|
| 2016 | 15時間47分 | - |
| 2015 | 70時間23分 | - |
| 年 | 実績 | 前年比 |
|---|---|---|
| 2016 | 6,501m | 29.72% |
| 2015 | 21,868m | - |
まあ2015年が元気すぎた。時間は有限なので、写真を撮りにいけばロードバイクに乗る時間は減るし……という当たり前のことではある。
とはいえ運動不足を解消するためにも2015年ほどと言わずとももう少し乗りたい気はする。
| 年 | 記事数 | 前年比 |
|---|---|---|
| 2016 | 161.45 | 94.41% |
| 2016 | 148 | 86.54% |
| 2015 | 171 | 54.11% |
| 2014 | 316 | - |
減少傾向にある。家にいる時間が減ったからだろうか。そもそも2014年はプライベートでいろいろあってずっとなにか書いていた気がするし、2015年くらいがいつもの調子だったかも。
これらに加えてアフィリエイト収入について書いた (雀の涙ほど) けれど Amazon の規約的に公開するのはよくなかった気がするので省略。
趣味のことでもいろいろ数字を出してみると発見があっておもしろい。
ここでは書いていないけれど、入社して以来、月収を額面、控除額などつぶさにしてスプレッドシートに記録していて、毎月給料日に記録するたび控除額を書き入れて暗い気持ちになるし、ここ3年の控除額の推移を見るとさらに暗くなる。
今年は光熱費などの推移も記録していきたい。今年もよろしくおねがいします。
*1:月100万までが現実味を感じられる
この記事では、安全にデプロイ方式を変えたプロセスを順を追って紹介します。
はてなブログは1日あたり平均して1.02回デプロイを行っています。これは土日を除いた週5日の営業日に対する平均です。ざっくりとした算出で、祝日は考慮していません。5月と9月の祝日を含めるともう少し多くなるかもしれません。
また、原則として休日の前日にはデプロイしないことになっています。もしもデプロイした変更にバグがあった場合、休日が明けてから対応するか、さもなくば休日中に対応する必要があります。 安定したサービスの提供のためと、開発メンバーの精神衛生のためにチームで取り決めました。
はてなブログのデプロイにかかる時間を Mackerel のサービスメトリクスとしてプロットしています。

従来、はてなブログのデプロイには1回あたりおよそ300秒ほどかかっていました。
なお、ここでいうデプロイとは bundle exec cap deploy をシェルで実行して各ホスト上に変更が行き渡るまでの一連の流れを指します。
1回あたり300秒ということは、デプロイした変更に致命的な不具合があって変更を巻き戻したり修正をデプロイするためにさらに300秒かかるということです。
念入りに QA を行ったり、テストを充実させたり、事前に不具合を混入させない努力はもちろん行うべきですしはてなブログでも取り組んでいますが、根絶することは現実的ではありませんし悪い事態に陥ったときのことも欠かさず考えなければいけません。
リカバーに時間がかかる状況ではリスクのある変更をためらってしまいますし、事故が起きたときの影響・損失はできるだけ小さく留めたいものです。
遅いという現状がわかったところで実際にデプロイの仕組みへ手を入れて高速化を図りたいところですが、 Capistrano 2 と古い社内ライブラリを組み合わせた上、Thread を直接使い並列実行するためにほとんど魔改造といって良いほどの状態で、手を出しかねていました。
Capistrano 2 と古い社内ライブラリ、そしてはてなブログ独自の設定と、3つの実装のかけ算により複雑さは極まっていました。
このような状態で変更を加えようとしても、良くて袋小路に入って時間を浪費してしまう程度、悪ければ致命的な不具合により障害に繋がります。
そこでまずデプロイで起きる変更の仕様をテストコードへまとめ検証可能にしました。 テストが書けた・書こうという気持ちが挫けなかったのは「何が起きているかはわかるが、どうして起きているかわからない」類のコードだったからとも思います。
デプロイの仕様とはなんでしょうか? end-to-end 的に考えると「追加・変更された機能を使えるようになる」ことでしょうが、あまりに漠としてテストへ落とし込みづらいです。
これから書こうとしているテストは開発者向けなのでよりホワイトボックス的に「任意のバージョンのアプリケーションがホスト上に配置され、アプリケーションプロセスが再起動される」とします。
より細かくは:
/apps/Hatena-Blog/releases/$VERSION)/apps/Hatena-Blog/current -> /apps/Hatena-Blog/releases/$VERSION)……くらいに分けられそうです。
アプリケーションが再起動したか確かめる方法は悩みましたが、後述するようにテストを実行する際はホストをロードバランサから外すため、リクエストを受け付けることはないという前提を立てて、アクセスカウンタがリセットされたことを指標に据えます。
リモートのホスト上でファイルシステムなどを見てアサーションを行うくらいであれば SSH 越しにシェルスクリプトを実行するくらいでもよいのですが、自動実行し、テスト結果を収集するところまで考えるとより高水準なフレームワークを使いたいところです。
まさしくこのような用途のためのフレームワークとして Serverspec があります。
たとえば「ワーキングディレクトリ (= /apps/Hatena-Blog/current) がデプロイしたいバージョンのディレクトリの symlink になっている」アサーションは以下のように書けます:
describe file('/apps/Hatena-Blog/current') do it 'is a symlink' do expect(subject).to be_symlink end it 'is linked to releases' do expect(subject.link_target).to be_start_with('/apps/Hatena-Blog/releases/') end end
「Plack::Middlware::ServerStatus::Lite のアクセスカウンタがリセットされている」アサーションは、素朴にレスポンスボディから正規表現でアクセス数を抽出します:
describe 'total access' do it 'looks like restarted' do total_accesses = `curl -s http://#{host}:#{port}/server-status`. each_line. grep(/\ATotal Accesses:/) {|l| l[/\ATotal Accesses: (\d+)/, 1] }. first.to_i expect(total_accesses).to be < 10 # デプロイ直後は10回もアクセスがきていないだろう end end
テストフレームワークの実装そのものは RSpec なので RSpec のフォーマッタがそのまま使えます。JUnit 形式の XML を出力するフォーマッタを導入すれば Jenkins でテスト結果を収集するのも簡単です。
これでデプロイを行って事後条件が満たされているか自動テスト可能な状態になりました。
次はより高速なデプロイの仕組みについて検討します。
はてなブログのデプロイのボトルネックを明らかにするため、デプロイの所要時間をより細かに見てみます。
Capistrano によるデプロイはアプリケーションコードの配布 (deploy:update) やプロセスの再起動 (deploy:restart) などいくつかのタスクに分割され、それらを逐次 (あるいは並列に) 実行していき、すべて完了したらデプロイが完了、というモデルです。
そこで各タスクごとそれぞれにかかった時間を計測し、各タスクを Mackerel のグラフ定義の1メトリックとしさらに積み上げグラフにすることで、デプロイ全体にかかった時間を詳細に可視化してみます。
参考: Mackerel のグラフ定義
文章で表現すると煩雑で伝わりにくそうですが、実際のグラフを見るとわかりやすいでしょう:
update_elapsed が支配的であることがわかります。 update_elapsed は deploy:update の実行にかかった時間です。
実際、デプロイ中も deploy:update で待たされる印象が強かったので主観とも一致しています。ここを改善できるとよさそうです。
なぜこんなにも時間がかかるかというと、中央の Git リポジトリからアプリケーションコードの変更を取ってくるアーキテクチャになっているのですが、この Git リポジトリがスケールしないためです。
詳しくは YAPC::Asia Tokyo 2015 で発表した「世界展開する大規模ウェブサービスのデプロイを支える技術」を参照してください。
さて、Git リポジトリがボトルネックとわかったのですが、他にアプリケーションコードの配布の方法を考えてみると上記発表でも触れたソースコードをひとつのファイルにまとめて HTTP でダウンロードする方法が挙げられます。
むしろアプリケーションの配置を VCS からソースコードを取得するだけで済ませるというのは、事前のコンパイルを必要としないインタプリタ言語かつ Web アプリケーションという限定的なシチュエーションでのみ実現できることで、むしろ1ファイルにまとめてダウンロードさせるという方法はより古典的でありふれているでしょう。
ソースコードをまとめたアーカイブファイルを各ホストにダウンロードさせるよう指示するデプロイを仮に push 型デプロイとしますが、この push 型デプロイで高速化できるか・スケールさせられるかは、既に上記発表にあるように検証済みなので、新デプロイ方式は push 型デプロイにすることとなりました。
次は実際に新デプロイ設定を書きます。
既存の設定をベースに書き換えていくこともできますが、今回はスクラッチから書いていくことにし、リポジトリもアプリケーションコードとは別のリポジトリを作りました。
そもそも既存の設定が秘伝のタレ化して行き詰まっていたという背景がありますし、古い社内ライブラリは Git リポジトリからアプリケーションコードを配布するアーキテクチャを前提とした便利ライブラリという体裁が強いので、もはや有用ではなくなります。
新たなデプロイ設定は、まずステージング環境のデプロイに導入しました。アプリケーションの開発と同じように、まずスコープを狭めて安全な砂場で試します。
次にロードバランサから外した一部のホストのみにデプロイし、前述したテストを実行し、期待する事後条件を満たすか確認します。
Web アプリケーションを実行するホストだけではなくバッチジョブを実行するホストなどでも同様に検証し、問題なくデプロイされたことを確かめた後に、サービスのホスト全体のデプロイをついに移行しました。
念入りにテストを書いたりコードレビューをしてもらってはいるものの、やはり稼働中のサービスのデプロイ方法を変える瞬間ほど緊張した瞬間はなかなかありません。
幸いなことに事前の準備が功を奏し無事故で移行でき、現在も push 型方式でデプロイしています。

従来の方式ではおよそ300秒ほどかかっていたデプロイが、新方式では平均でおよそ 50秒 に短縮されました。実に約6倍の高速化です。
従来は年間でおよそ20時間近く待ち時間が発生していましたが、新しい方式では年間3時間ほどに短縮されました。
不具合などによりリカバーを行う場合や、はてなブログチームでは導入していませんが Site Reliability Engineering における error budget に対するインパクトも大きく変わりえます。
『継続的デリバリー』の p.68 より:
開発・テスト・リリースプロセスを自動化することで、ソフトウェアをリリースする際のスピードや品質、コストがかなりの影響を受ける。 ......それによってビジネス上の利益をより素早く提供できるようになる。リリースプロセス自体の敷居が下がっているからだ。
今回のデプロイ改善は直接利益をもたらすものではありませんが、リリースマスターの拘束時間が減ることにより心理的な負担が減るなど、はてなブログというサービスを改善し安定した提供を続けるためにポジティブな影響を与えています。
はてなブログのデプロイを高速化した背景と導入のステップについて紹介しました。
この記事では紹介しませんでしたが、実際にデプロイを高速化したことで障害に繋がることを防げたこともあります。 エンジニア個人としても普段行うデプロイが速く済むのは数字以上に快適で達成感もありました。
この記事は、はてなエンジニアアドベントカレンダー2016の16日目の記事です。
昨日は ![]() id:amagitakayosi でした。明日は
id:amagitakayosi でした。明日は ![]() id:ikesyo です。
id:ikesyo です。
お題「エンジニア立ち居振舞い」 ということでエンジニアの立ち居振舞いについて書きます。
今いるチームでは毎日午後からレビュータイムということでレビュー依頼された Pull Request を見ています。

最近、他のチームからレビュー依頼が消化されなくて頑張って見ているけど大変という相談を受けたりしたのですが、今いるチームではどうしているかというと、毎日レビュー依頼ラベルがついている Pull Request がなくなるまでレビューを続けます。
コードレビューの具体的なテクニックなどは別の機会にとっておくこととしますが、以下のような記事などが参考になると思います:
レビュータイムの導入・消滅・再導入 - $shibayu36->blog;
レビュー依頼されているということは、リリースまでに残る主な工程はコードレビューを受けるくらいでしょう。ということは、コードレビューが滞ると完全にブロックされてしまいます。
チームとしてコードレビューが滞ると、いつリリースできるか見立てが立てづらくなってしまいます。
ずっとコードレビューをしていると他のタスクがリリースできないのでは? という懸念があるかもしれませんが、そもそもコードレビューが滞っていてはリリースはできないため、コードレビューの時間を減らしたところで払うべき労力を先延ばしにしているだけといえそうです。
どのみちかけるべき労力であるならば、すばやく見てフィードバックを返すほうが健全という気持ちで日々、レビュー依頼をすばやくなくなるまで見ています。
最近、レビュー依頼ラベルがついたら Slack で教えてくれるようになったので、レビュータイム以外でも気がついて手があいたら見るようにしています。

このように毎日コードレビューし・されています。みなさまの立ち居振舞いを教えてください。
普段、Perlを書くときは require_ok などでモジュールがコンパイル可能か・構文エラーがないかをテストするようにしているけれど、 require_ok では発見できない構文エラーを発見したのでそれの詳細と対策について。
実行時エラーに構文エラーになることなんてあるのかよと思うけど、厳密には構文エラーではなく、意図しない構文解析の結果、コンパイルは成功するが実行するとエラーになるというコードができあがってしまった。
具体的には以下のようなコード:
package App::Logger; use Exporter 'import'; our @EXPORT = qw(INFO); sub INFO ($;@) { ... } 1;
package App::Loader::User; sub find { local $@; eval { ... }; if ($@) { INFO $@; } } 1;
App::Logger はいろいろ便利なことをしてくれるアプリケーションロガーで定義されたサブルーチン INFO はprototypeが宣言されており INFO 'hi'; INFO 'user: %s', $user->name; のように呼び出せる。
App::Loader::User は App::Loader::INFO を呼び出しているパッケージだけど、 use App::Logger するのを忘れていた。しかしコンパイルは通る。つまり構文解析には成功しているということである。なぜだろうか?
具体的には INFO $@; がなぜ構文解析に成功するのか。答えはindirect object notationとして妥当な構文であるからだった。
indirect object notationはperldoc perlmodに詳しいが、 MOD->METHOD という呼び出しは METHOD MOD と等しく、後者をindirect object notationという。
つまり INFO $@ は $@->INFO と構文解析されて妥当というわけである。
謎は解けたが、ひとつのことを成し遂げるために複数のやりかたがあるという状態は、特にチーム開発においてはうれしいことばかりではない。堅牢にソフトウェアを作るためには、曖昧さが少なくエンバグのおそれが少ない書き方ができるほうが望ましい。
indirect object notationを意図せず使っていたら警告なりしてほしいところだけど、そんなときはindirectプラグマが使える。
no indirect; を書いたスコープでindirect object notationが使われていると警告される。 no indirect 'fatal'; で警告する代わりに例外を投げる。
プラグマの影響範囲はデフォルトでレキシカルだけど no indirect 'global'; でグローバルに有効にできる。
これでindirect object notationでハマることを減らせそうで助かってめでたいですね。
小学生のころにレンズ付きフィルムを少し使ったくらいで、カメラといえばデジタルの自分にとって長らく写真は、親に言われるまま渋々と学校行事のスナップ写真を注文して買うだけのものだった。
高校生のころ、京都や東京で淡々と、あるいは鬱屈と撮った写真をぽつりと載せ続ける Web サイトを見続けて、いつか自分もこの人と同じものを見たいと感じて調べた結果、デジタル一眼レフカメラの存在を知り貯金をはじめた。
いろいろなカメラに目移りしつつも、直線が多く精悍なかたちに惹かれて PENTAX K-7 を選んだ。


真冬の北海道は屋外と屋内の温度差が激しくカメラには過酷な環境であるにも関わらず毎日裸で持ち出してはなんでもない風景を撮り続けた。
進学で大阪に引っ越してからもそれは変わらず、新生活に寄せていた期待は裏切られ友人もできず暗い気持ちで過ごす毎日を捉え続けたのはPENTAX K-7だった。

このカメラに足を引っ張られたことは一度もなく、雨が降ろうと雪が降ろうと真夏の炎天下だろうと、どれだけ厳しくても静かに風景を捉えつづけてくれた。先に根を上げるのはきまって自分。
そのあと PENTAX K-3 に買い替えてからは防湿庫にいることが多かったが、とうとう今年の春、手元を離れていった。
代わりにやってきたのは PENTAX K-1. PENTAX K-7 から変わらず手に馴染み、今年も、これからもきっと自分が死ぬまでシャッターを切り続けるでしょう。いつも先に根を上げてしまうのは自分だったから。
春なので4年前くらいにコップ本の初版を読んで以来の Scala を書きます。

vim-scala を入れて構文ハイライトなどを手に入れます。
syntastic は後述する vim-ensime が syntastic のコマンドを呼んでおり、インストールしていないとエラーが出るので導入しました。
(もともと syntastic を使っていたのですが、非同期実行ができなかったのでブロックされてしまい使うのをやめていました。)
せっかくなので lightline.vim で構文チェック結果を表示するようにしました:
ENSIME brings Scala and Java IDE features to your favourite text editor
ENSIME とは IDE が提供するような定義元へのジャンプや型の表示などのリッチな機能を提供するツールです。
ENSIME は、ビルドツールと統合してプロジェクトの設定を書き出し (.ensime)、エディタが JVM のプロセスを起動し TCP (WebSocket) で通信するというアーキテクチャになっています。
ドキュメントに書いてあるようにいくつかのエディタ、いくつかのビルドツールがサポートされています。
ensime-vim は、ENSIME という IDE が提供するような定義元へのジャンプや型の表示などのリッチな機能を提供するツールの Vim 用クライアントを提供するプラグイン。
一時は開発が停滞しており使い物にならなかったそうですが、今はわりと活発に開発されているようでドキュメントに書いてあるとおりに導入したところちゃんと動いて使えています。
vim-ensime は Python インターフェースから WebSocket で ENSIME のプロセスと通信するという実装になっています。
websocket-client という pip パッケージを入れる必要があるので、OS X の Python に sudo を使って入れたくないので Homebrew で入れた Python を使います。
……が、手元に入れていた MacVim はシステムの Python にリンクしていたので python/dyn が使えるよう MacVim をビルドします。
brew unlinkapps brew unlink macvim brew tap macvim-dev/macvim brew install --with-properly-linked-python2-python3 --HEAD macvim-dev/macvim/macvim brew linkapps macvim-dev/macvim/macvim
✘╹◡╹✘ < vim --version | grep python +cryptv +linebreak +python/dyn +vreplace +cscope +lispindent +python3/dyn +wildignore
okok.
公式のインストール手順に書いてあるとおり sbt プラグインをインストールするだけ。
手を動かします。
はてなインターン事前課題をやって、はてな教科書を読んで課題を進めます。Scala で Web アプリケーションを書くにあたってひととおりなにか書くにあたって、課題がまとまっていてよいです。
コップ本を片手に Scala API リファレンス を眺めるのも乙なものです。
(ひさしぶりに) Scala を書くにあたっていろいろ環境を整えたり、Scala を書く際の勘所を得る (取り戻す) ためにコードを書いたり資料を読んだりしました。
次は Play でちょっとしたアプリケーションを書いたので、その記録です。
シェルなどの設定の知見が意外と広まってないよね、ということで話題になったので書きました。
https://github.com/aereal/dotfiles/blob/1be211fcda027f75b0624eab2c44a288f8e0691e/.zshrc#L174
Vim 使っていると :q したくなるので alias をつくった。
https://github.com/aereal/dotfiles/blob/1be211fcda027f75b0624eab2c44a288f8e0691e/.zshrc#L109-L120
~/ はけっこう使うわりに押しにくいので、バックスラッシュを入力したら ~/ に展開するようにしてある。
カーソル位置の左が空白か行頭の場合のみ展開する、という風にしているので echo 'a\'' などは普通に入力できる。
https://github.com/aereal/dotfiles/blob/1be211fcda027f75b0624eab2c44a288f8e0691e/.zshrc#L153-L171
C-w v とか C-w s で、現在プロンプトに入力しているコマンドを分割したあとのペインで実行する。
tail -F /var/log/app/fluentd.log[C-w]v などと入力すると縦分割してログを眺められて便利。
エスケープが雑なのと、分割したペインでは新たに tmux 経由でシェルが実行されるので環境変数が引き継がれないなどあるけど、だいたい便利に使えている。
https://github.com/aereal/dotfiles/blob/1be211fcda027f75b0624eab2c44a288f8e0691e/.zshrc#L15
REPORTTIME に指定した時間より長くかかったコマンドの終了時に、自動的に time の結果を出力する。
GitHub - aereal/vim-colors-japanesque: The colorscheme featuring Japanese traditional colors.
GUI 版の Vim 向けカラースキーム・Japanesque を作った。
iTerm 2 で使えるカラースキーム、Japanesque を作った - Sexually Knowing
以前、iTerm 向けに作った同名のカラースキームを踏襲しつつ新たにパレットから作った。
コンセプトとしては:
……とした。
" neobundle.vim NeoBundle 'aereal/vim-colors-japanesque' " Vundle Bundle 'aereal/vim-colors-japanesque' " vim-plug Plug 'aereal/vim-colors-japanesque'
あるいは colors/japanesque.vim を $VIMRUNTIME/colors/ 以下に配置するなど。
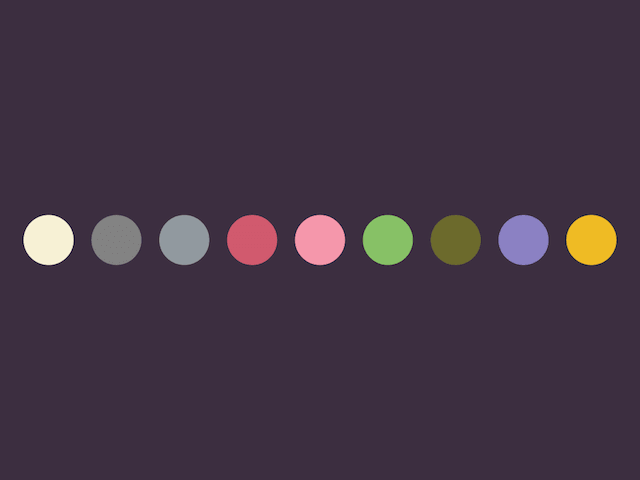
……以上の9色を基本のカラーパレットとしている。
紫は、古来から高貴であるとされて尊ばれていること、カラーパレット上のどの色との相性がよいこと、寒色とも暖色ともつかず機能的に中立的であることなどから背景色として、カラースキームの方向性を決定づける役割を与えた。
カラーコードは引き続き NIPPON COLORS - 日本の伝統色 を参照している。
もともと Solarized の暗い背景モードの配色を気に入っておらず、カラースキームを作ることを考えていたところに上記の記事を読んで共感し、iTerm のカラースキームとして作って気に入っていた Japanesque を Vim 向けに一から作ろうと決めた。
カラーパレットを上記の通り決めて、次に構文要素にどのような色 (役割) を与えるか考える。
カラースキームは、ソースコードの注目すべき領域とそうでない領域を色で表現することで、理解を助けるはたらきがあると思う。つまり、ソースコード中でどのような要素に着目すべきか考えるとよさそう。
ソースコードに出現するトークン (識別子) は大きく分けて:
……のように分類できると考えてみる。
上から下に行くほど情報の凝集度が高まり、生存期間は短くなる。制御構造はプログラムの実行開始から終了まで消えることはないだろうし実質的に無限と考えられる。
情報の凝集度が高いほど重要なので、識別子としてより目立たせるという作戦を立てた。制御構造などのコントラストは下げ、ローカル変数やプロパティはコントラストを上げるという作戦にした。
Ruby のスクリーンショットを見ると雰囲気は伝わると思う。
現時点では:
……が欠けているので対応しようと思っている。
他、優先度は高くないが色覚障害の対応状況はチェックしたい。
その他エディタへの移植リクエストやバグ報告などは GitHub の Issues にいただけると助かります。ほか Twitter でも。
GitHub - aereal/psi-metrics: Post PageSpeed Insights score to Mackerel
ユーザが体感するページの読み込み速度を100点満点で評価するサービス。画像を圧縮せよとか HTTP キャッシュを使えとか、とにかく Web ページを速くするためのアドバイスをしてくれる。
チームで指標のひとつとして月1で眺めている。
Google PageSpeed Insights には API がある。
Web のインターフェースでとれる情報はほとんど JSON で返ってくる。スコアだけではなくて、各ルール (例: 画像を圧縮せよ) ごとのスコアと説明も構造化されて含まれているのでその気になれば Google PageSpeed Insights の Web 版を作り直すこともできる (やりたくはない)。
毎月1回しか見ていなくて、そのあいだにどういう変動があったかは追えていない。とはいえ毎日見たくはない。
そこで Mackerel のサービスメトリクスにする。ルールごとのスコアもあるがひとまずトータルのスコアだけ見れればよさそう。
サービスメトリクスにした様子:

できたものの定期的に実行する必要があるので手頃な Heroku にデプロイすることにした。とはいえ過去の経験からして素朴に `heroku config:set ...` などしていくと、後になってどういう設定をすればまず動くのか、といったことがわからなくなるので対策しなければならなかった。
そこで Deploy to Heroku ボタンのことを思い出した。
Introducing Heroku Button | Heroku
リポジトリに app.json を書いておくと必要な設定をフォームで埋めて送信するだけでアプリケーションがデプロイできるというもので、設定の説明を書いてなおかつ再利用なかたちになるのでさっと app.json を用意した。
app.json や Deploy to Heroku ボタンは Heroku のドキュメントがわかりやすい:
Deploy to Heroku ボタンを押していますぐ Mackerel で PageSpeed Insights のメトリクスを作りパフォーマンスの監視をしてみましょう。
cap log するとデプロイ時に観察したいログがとにかく tail できるということになっている。
しかしまとめて流れてくるので、どのホストからなのかなどわからなくて少し困る。ので、出力にホスト名とファイル名を含めるようにした。
出力の例:
[xxx.xxx.xxx.xxx (/service/My/log/main/current)]: 2016-02-23 16:29:02.292284500 Use of uninitialized value in string ne at lib/My/Service/Post.pm line 178. [xxx.xxx.xxx.xxx (/service/My/log/main/current)]: 2016-02-23 16:29:02.292285500 Use of uninitialized value in string ne at lib/My/Service/Post.pm line 178. [xxx.xxx.xxx.xxx (/var/log/app/workermanager.log)]: 2016-02-23T16:29:51 TheSchwartz TheSchwartz::work_once got job of class 'My::Worker::SomeDelayedTask', priority 80 [xxx.xxx.xxx.xxx (/var/log/app/workermanager.log)]: 2016-02-23T16:29:51 TheSchwartz Working on My::Worker::SomeDelayedTask ... [xxx.xxx.xxx.xxx (/var/log/app/workermanager.log)]: 2016-02-23T16:29:53 TheSchwartz TheSchwartz::work_once got job of class 'My::Worker::SomeDelayedTask', priority 80 [xxx.xxx.xxx.xxx (/var/log/app/workermanager.log)]: 2016-02-23T16:29:53 TheSchwartz Working on My::Worker::SomeDelayedTask ... [xxx.xxx.xxx.xxx (/var/log/app/workermanager.log)]: 2016-02-23T16:29:54 TheSchwartz job completed My::Worker::SomeDelayedTask process:2401 delay:1968 [xxx.xxx.xxx.xxx (/service/My/log/main/current)]: 2016-02-23 16:29:55.907968500 Use of uninitialized value in string ne at lib/My/Service/Post.pm line 178. [xxx.xxx.xxx.xxx (/service/My/log/main/current)]: 2016-02-23 16:29:55.907969500 Use of uninitialized value in string ne at lib/My/Service/Post.pm line 178.
Cap の run メソッドはコールバックを受け取ることができて、コールバックの引数に SSH のコネクションをあらわすオブジェクトが渡ってくる。
このオブジェクトから IP をもらってホスト上の出力を素朴に puts するだけ。
ホストの role とか出せるとよかったけど、手間そうだったのでログのファイル名を出せばわかるだろうということでこれくらいにした。
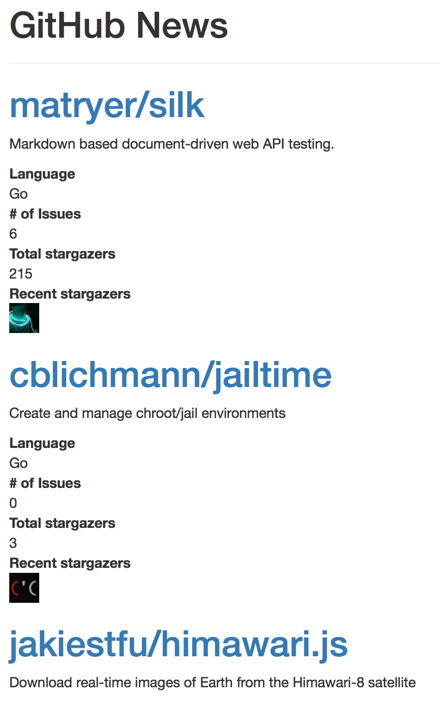
https://github.com/ や https://github.com/USER.private.atom?token=XXX で見れるタイムラインを見て他の人が star をつけたリポジトリをチェックするといったことをしているとき、どういうリポジトリなのか・言語はなにかなどを知りたいと思うことがしばしばあったので、いいかんじに表示する Web アプリケーションを書いた。
素朴に GitHub の API へリクエストを投げたらだいたい 1000msec * 25-30 くらいでレスポンスが返ってくるまで30秒くらいかかってさすがに耐え難いので並列化した。
しかし Thread を扱うにも同時並列数の制御がむずかしいので諦めて parallel という gem を使った。
いまは単に HTML を返すだけだけど Atom を吐くようにして Feedly あたりにつっこみたい。
あと Feeds API は BASIC (パスワード) 認証じゃないと private なフィードの URL を返してくれなかった。
Ruby ではメソッド内で定数を定義することは通常できない。
例:
def k K = 1 end # /Users/aereal/Dropbox/sketches/const.rb:2: dynamic constant assignment # K = 1 # ^
ちなみに dynamic constant assignment
は「メソッドの定義内で定数を定義できない」という意味でしかなく、以下の定義はすべて有効であり警告も出力されない ( Ruby 2.2.4 )。
if rand(10).floor.even? N = 0 else N = 1 end M = $M if rand(10).floor.even? K = 1 end # 定数 `K` を参照すると 1/2 の確率で NameError 例外が発生する。
定数なので静的な文脈で定義すればよいのだけれども、既に定義済みの定数を動的に書き換えたいことがある。たとえば OpenSSL::SSL::VERIFY_PEER など……。
さてメソッド内で定数を定義する方法はいくつか考えられる。
define_method を使うself.class.send(:define_method, :k) { K = 1 }
Kernel#.require で定数を定義する別ファイルを読み込むconst.rb:
K = 1
k.rb:
def k require 'const' K end
メタプログラミングすればだいたいなんとかなる Ruby のことなので、だいたいメタプログラミングなどでなんとかなった。
堅牢さが欲しいと思いつつも、いざとなればメタプログラミングでこじあけられるということは、ブラックボックスである部分が少なくなるということであり、いろいろなライブラリを組み合わせてアプリケーションを書くときにはけっこう助かることも多いですね。
2015-01-01から1年間の記事一覧 - Sexually Knowing
「安全にソフトウェアをつくる」ことが大きな関心であり、そのために CI (Jenkins) をよりディープに使おうとしたり、Ansible や Homebrew を活用していわゆる Configuration Management を進めた。
そのおかげで Ansible はかなり手に馴染んできた。実際に仕事にも活かせる場面が出てくるほどに。
APISchema を使っているのでいくらか P-R を送った。
参考: DSLでAPIを書きたい!!APISchemaでらくらくAPI生活をはじめよう - hitode909の日記
#yapcasia で『世界展開する大規模ウェブサービスのデプロイを支える技術』という発表をした - Sexually Knowing
また今年の YAPC::Asia 2015 Tokyo で2度目のトークの機会をいただけた。
世界展開する大規模ウェブサービスのデプロイを支える技術 / YAPC::Asia Tokyo 2015 // Speaker Deck
このトークで紹介した tarball を配るデプロイは他のチームでも一部導入を進めつつあり、そのうちいくらかコミットしている。
ごく個人的な感想として、こうしたカンファレンスでの発表をきっかけに開発を始めたりあるいは進めたり (= 発表ドリブン) することが多かったけれども、今回はまずある程度の形をなした成果があって、それをベースにして発表を組み立てる、という経験は初めてのことだった。
おかげで発表の内容を深めたり、そのために必要なベンチマークをとったりするなど充実した準備をした上で発表に臨むことができた。
(もっとも、いままでがリラックスしすぎていた、ということはあるかもしれない)
輪講で『実践ドメイン駆動設計』を読むことになって、『エリック・エヴァンスのドメイン駆動設計』を復習しつつ、DDD を実際に導入していくにはどうしたらいいんだろうね、ということを議論した。
輪講の場で実際のサービスの境界づけられたコンテキストやユビキタス言語を見出したり、実はあのシステムはここでいうイベントソーシングだったんだといった発見が得られたり、非常に実践的な知識が培われたと思う。
特に、実際のサービスのドメインモデルやアーキテクチャを再訪し省みるという試みはまさしく「実践」であり、我々が作ろうとしているものに DDD (あるいは別のやりかた) が適しているだろうか、適しているとしたらなぜなのか、といった深い検討を進められた。
犠牲的アーキテクチャのようなソフトウェアに寿命があるものと考えるある種の悲観的な見方もあるが、寿命を迎えたソフトウェアをただ塵に還すのか、なにか洞察を持ち帰るのかは、こういった試みの有る無しによるのだと思う。
参考: はてな社内で開催したDDD勉強会の様子をご紹介します - Hatena Developer Blog
")
実践ドメイン駆動設計 (Object Oriented SELECTION)
")
エリック・エヴァンスのドメイン駆動設計 (IT Architects’Archive ソフトウェア開発の実践)
『すごい Haskell 楽しく学ぼう!』を買って読んだ。断片的な知識しか身に付いていなかった Haskell について、ざっくばらんでもまとまった基礎的な知識を得られた。
Functor, Applicative Functor, Monad, Monoid, その他波及して、MonadPlus, Semigroup などについて (不完全あるいは不正確かもしれないが) ひととおり基礎的な背景知識が得られた。
新しいプログラミング言語を学ぶとき、新しい考え方を得て他の言語と比較し相対化するということに最も価値を感じており、たとえば Haskell ではいまのところ型クラスと Functor や Monad といった素朴ながら強力な抽象化のツールキットたちが大きな収穫となっている。
Haskell の型クラスは静的型付けと実装に対して開かれた抽象を実現する仕組みでとてもおもしろいし強力さを既に感じている。
自分は Ruby がけっこう好きで、その最も大きな理由としてオープンクラスを挙げるだろう。それと同等かそれ以上に強力な仕組みをコンパイル時に型検査が行われるという堅牢性と両立できているのは、よく考えられているなあ、と感動する。
Functor や Monad といったある種の計算に共通する属性を抽象化する型クラスたちに対する背景知識を得て、なるほどたしかに強力だと感じた。 現実の複雑な問題を解決するのに十分な力が、素朴なモデルに備わっているのはかっこいい。
おもしろかったので TypeScript の Generics や Abstract class の勉強がてら Maybe や State などの Monad を実装してみたり、Perl の Data::Monad というモジュールに Data::Monad::Either の実装を追加したりなど、それなりに実りもあった。
それに伴って Haskell の base パッケージや scalaz のコードを読んだ。 scalaz のコードリーディングは楽しくて、パターンマッチングのような言語の子細な仕様の違いから、型クラスの実現方法の違いなど、大小様々な差異が見取れて Scala の implicit conversion まわりについても少し理解が進んだ。
また、『すごい Haskell』本を読んで高まり、もっと足元を固めたいと思ってウィッシュリストに入れた『やさしく学べる離散数学』を hitode909 さんから贈っていただいて練習問題をやりつつ読み終えた。


変化の激しいフロントエンド界隈において落ち着きを見せはじめた ES2015 や TypeScript に触れはじめておもちゃを作ってみたり 本番投入を見据えたサービスで TypeScript を使いはじめたり、NPM モジュールを書いて公開するなどした。
あと redux と Electron のチュートリアルをやった。
2015年はインプットが進んだ一年だった。次の1年、あるいはその先をどうするか。おおまかには:
……を考えている。
高等教育をろくに受けておらず、特に数学や計算機科学はかなり怪しい。
とはいえ、そういった問題意識がありつつも、いまはシンプルにここらへんについてもっと知ることができたら楽しくなりそうだな、という好奇心のほうが強い。
おもしろそうなことを知りたい、という以上の理由はいらなさそうだし、結果的に仕事や趣味に役立ったらお得だな、という気持ち。
……という3つの小テーマがある。
UNIX 哲学の体現とは、『すごい Haskell』本で学んだ Monad など現実の問題に対処できる力を持った強力ながらシンプルなモデルが組み合わされて複雑な問題に立ち向かうことができればきっとうまくいくだろう、ということ。 つまり巨人 *1 の肩に乗るのが一番だということ。
アウトプットは文字通りで、1年間インプットしたわりに仕事のドメインに閉じがちなアウトプットだったので、もう少しオープンなものにしたい。 UNIX 哲学の体現とも関わりがあって、つまりいくつかのモジュールをプラガブルに組み立てて問題を解決したならばドメインロジックではない部分を分けられるはず。
ソフトウェア的としたのは、カンファレンスにおける発表を目標に据えるとしても、まずソフトウェアエンジニアとして問題を解決した・するという成果がなければだめで、自分にとって手近かつイメージしやすい成果とはつまりソフトウェア、それも OSS をつくることだろう、というところによる。
具体的なイメージとしては @substack 氏かもしれない。
CI で実行すべき処理をシェルスクリプトなどにしてリポジトリに含めておく、というのはまっとうな管理というかんじで望ましい。
とはいえ、新しく CI のジョブを追加するなどして新しいスクリプトをリポジトリに追加した場合、追加するコミットが含まれていない古いブランチの扱いをどうするか、という悩みは尽きない。
作戦としては:
……という2つが考えられて、いままでは後者をとってきた。
しかし、メンテナンスすべきところが2つあると億劫だし、たまに修正が漏れたりする。
そこで、次のようなやりかたをとってみる:
git-cat-file で内容を出力してパイプして実行する「必ず存在するブランチ」とは、master など統合ブランチでもよいし、あるいはトピックブランチでもよい。
SHA1 で特定のコミットを指してもいいけど、リポジトリでバージョン管理したいという旨からするとブランチのほうが望ましいように思う。
具体的には以下のようなかんじ。
CI で実行したいスクリプト:
#!/bin/bash set -e -u carton install carton exec -- prove t/
CI の設定 (シェルスクリプト):
ci_script=script/ci/run if [[ -f $ci_script ]]; then bash $ci_script else git cat-file blob origin/add-ci-script:$ci_script | bash - fi
こうしておくと CI の設定は最小限度で済むし、基本的にそのブランチごとの最新のスクリプトが実行されるのでバージョン管理の恩恵が受けられる。
あと、細かい点ではあるけれどもパイプして実行しているのでごみを残さないのもよい (( ファイルを残しておくとうっかり同名のファイルをリポジトリに追加すると git-checkout に失敗してしまう ))。

