- 今年、稼働中のサービスであるはてなブログのデプロイ方法を新しい方式へ無事故で移行し、従来と比べて約6倍速くデプロイできるようになりました。
この記事では、安全にデプロイ方式を変えたプロセスを順を追って紹介します。
はてなブログと継続的デリバリー
はてなブログは1日あたり平均して1.02回デプロイを行っています。これは土日を除いた週5日の営業日に対する平均です。ざっくりとした算出で、祝日は考慮していません。5月と9月の祝日を含めるともう少し多くなるかもしれません。
また、原則として休日の前日にはデプロイしないことになっています。もしもデプロイした変更にバグがあった場合、休日が明けてから対応するか、さもなくば休日中に対応する必要があります。 安定したサービスの提供のためと、開発メンバーの精神衛生のためにチームで取り決めました。
デプロイが遅い
はてなブログのデプロイにかかる時間を Mackerel のサービスメトリクスとしてプロットしています。

従来、はてなブログのデプロイには1回あたりおよそ300秒ほどかかっていました。
なお、ここでいうデプロイとは bundle exec cap deploy をシェルで実行して各ホスト上に変更が行き渡るまでの一連の流れを指します。
1回あたり300秒ということは、デプロイした変更に致命的な不具合があって変更を巻き戻したり修正をデプロイするためにさらに300秒かかるということです。
念入りに QA を行ったり、テストを充実させたり、事前に不具合を混入させない努力はもちろん行うべきですしはてなブログでも取り組んでいますが、根絶することは現実的ではありませんし悪い事態に陥ったときのことも欠かさず考えなければいけません。
リカバーに時間がかかる状況ではリスクのある変更をためらってしまいますし、事故が起きたときの影響・損失はできるだけ小さく留めたいものです。
複雑なデプロイ設定
遅いという現状がわかったところで実際にデプロイの仕組みへ手を入れて高速化を図りたいところですが、 Capistrano 2 と古い社内ライブラリを組み合わせた上、Thread を直接使い並列実行するためにほとんど魔改造といって良いほどの状態で、手を出しかねていました。
Capistrano 2 と古い社内ライブラリ、そしてはてなブログ独自の設定と、3つの実装のかけ算により複雑さは極まっていました。
このような状態で変更を加えようとしても、良くて袋小路に入って時間を浪費してしまう程度、悪ければ致命的な不具合により障害に繋がります。
そこでまずデプロイで起きる変更の仕様をテストコードへまとめ検証可能にしました。 テストが書けた・書こうという気持ちが挫けなかったのは「何が起きているかはわかるが、どうして起きているかわからない」類のコードだったからとも思います。
デプロイのテストを書く
デプロイの仕様とはなんでしょうか? end-to-end 的に考えると「追加・変更された機能を使えるようになる」ことでしょうが、あまりに漠としてテストへ落とし込みづらいです。
これから書こうとしているテストは開発者向けなのでよりホワイトボックス的に「任意のバージョンのアプリケーションがホスト上に配置され、アプリケーションプロセスが再起動される」とします。
より細かくは:
- 任意のバージョンのアプリケーションが配置される
- 任意のディレクトリにアプリケーションコードが配置されている (e.g.
/apps/Hatena-Blog/releases/$VERSION) - ワーキングディレクトリがデプロイしたいバージョンのディレクトリの symlink になっている (e.g.
/apps/Hatena-Blog/current -> /apps/Hatena-Blog/releases/$VERSION) - アプリケーションが再起動される
- Plack::Middleware::ServerStatus::Lite のアクセスカウンタが0になっている
……くらいに分けられそうです。
アプリケーションが再起動したか確かめる方法は悩みましたが、後述するようにテストを実行する際はホストをロードバランサから外すため、リクエストを受け付けることはないという前提を立てて、アクセスカウンタがリセットされたことを指標に据えます。
リモートのホスト上でファイルシステムなどを見てアサーションを行うくらいであれば SSH 越しにシェルスクリプトを実行するくらいでもよいのですが、自動実行し、テスト結果を収集するところまで考えるとより高水準なフレームワークを使いたいところです。
まさしくこのような用途のためのフレームワークとして Serverspec があります。
たとえば「ワーキングディレクトリ (= /apps/Hatena-Blog/current) がデプロイしたいバージョンのディレクトリの symlink になっている」アサーションは以下のように書けます:
describe file('/apps/Hatena-Blog/current') do it 'is a symlink' do expect(subject).to be_symlink end it 'is linked to releases' do expect(subject.link_target).to be_start_with('/apps/Hatena-Blog/releases/') end end
「Plack::Middlware::ServerStatus::Lite のアクセスカウンタがリセットされている」アサーションは、素朴にレスポンスボディから正規表現でアクセス数を抽出します:
describe 'total access' do it 'looks like restarted' do total_accesses = `curl -s http://#{host}:#{port}/server-status`. each_line. grep(/\ATotal Accesses:/) {|l| l[/\ATotal Accesses: (\d+)/, 1] }. first.to_i expect(total_accesses).to be < 10 # デプロイ直後は10回もアクセスがきていないだろう end end
テストフレームワークの実装そのものは RSpec なので RSpec のフォーマッタがそのまま使えます。JUnit 形式の XML を出力するフォーマッタを導入すれば Jenkins でテスト結果を収集するのも簡単です。
これでデプロイを行って事後条件が満たされているか自動テスト可能な状態になりました。
次はより高速なデプロイの仕組みについて検討します。
ボトルネックの発見、そして pull 型から push 型のデプロイへ
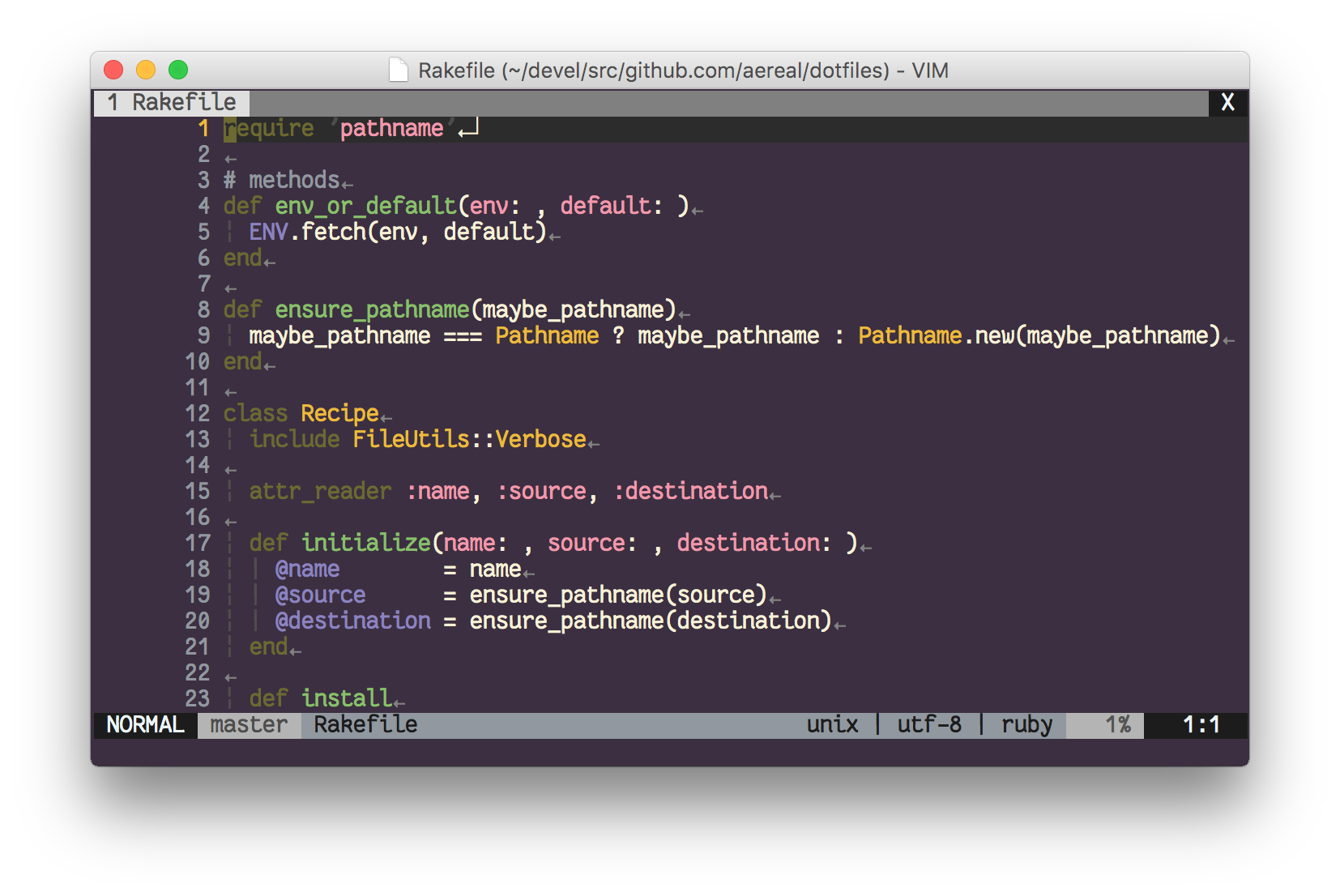
はてなブログのデプロイのボトルネックを明らかにするため、デプロイの所要時間をより細かに見てみます。
Capistrano によるデプロイはアプリケーションコードの配布 (deploy:update) やプロセスの再起動 (deploy:restart) などいくつかのタスクに分割され、それらを逐次 (あるいは並列に) 実行していき、すべて完了したらデプロイが完了、というモデルです。
そこで各タスクごとそれぞれにかかった時間を計測し、各タスクを Mackerel のグラフ定義の1メトリックとしさらに積み上げグラフにすることで、デプロイ全体にかかった時間を詳細に可視化してみます。
参考: Mackerel のグラフ定義
文章で表現すると煩雑で伝わりにくそうですが、実際のグラフを見るとわかりやすいでしょう:
update_elapsed が支配的であることがわかります。 update_elapsed は deploy:update の実行にかかった時間です。
実際、デプロイ中も deploy:update で待たされる印象が強かったので主観とも一致しています。ここを改善できるとよさそうです。
なぜこんなにも時間がかかるかというと、中央の Git リポジトリからアプリケーションコードの変更を取ってくるアーキテクチャになっているのですが、この Git リポジトリがスケールしないためです。
詳しくは YAPC::Asia Tokyo 2015 で発表した「世界展開する大規模ウェブサービスのデプロイを支える技術」を参照してください。
さて、Git リポジトリがボトルネックとわかったのですが、他にアプリケーションコードの配布の方法を考えてみると上記発表でも触れたソースコードをひとつのファイルにまとめて HTTP でダウンロードする方法が挙げられます。
むしろアプリケーションの配置を VCS からソースコードを取得するだけで済ませるというのは、事前のコンパイルを必要としないインタプリタ言語かつ Web アプリケーションという限定的なシチュエーションでのみ実現できることで、むしろ1ファイルにまとめてダウンロードさせるという方法はより古典的でありふれているでしょう。
ソースコードをまとめたアーカイブファイルを各ホストにダウンロードさせるよう指示するデプロイを仮に push 型デプロイとしますが、この push 型デプロイで高速化できるか・スケールさせられるかは、既に上記発表にあるように検証済みなので、新デプロイ方式は push 型デプロイにすることとなりました。
次は実際に新デプロイ設定を書きます。
新デプロイへの移行
既存の設定をベースに書き換えていくこともできますが、今回はスクラッチから書いていくことにし、リポジトリもアプリケーションコードとは別のリポジトリを作りました。
そもそも既存の設定が秘伝のタレ化して行き詰まっていたという背景がありますし、古い社内ライブラリは Git リポジトリからアプリケーションコードを配布するアーキテクチャを前提とした便利ライブラリという体裁が強いので、もはや有用ではなくなります。
新たなデプロイ設定は、まずステージング環境のデプロイに導入しました。アプリケーションの開発と同じように、まずスコープを狭めて安全な砂場で試します。
次にロードバランサから外した一部のホストのみにデプロイし、前述したテストを実行し、期待する事後条件を満たすか確認します。
Web アプリケーションを実行するホストだけではなくバッチジョブを実行するホストなどでも同様に検証し、問題なくデプロイされたことを確かめた後に、サービスのホスト全体のデプロイをついに移行しました。
念入りにテストを書いたりコードレビューをしてもらってはいるものの、やはり稼働中のサービスのデプロイ方法を変える瞬間ほど緊張した瞬間はなかなかありません。
幸いなことに事前の準備が功を奏し無事故で移行でき、現在も push 型方式でデプロイしています。
結果

従来の方式ではおよそ300秒ほどかかっていたデプロイが、新方式では平均でおよそ 50秒 に短縮されました。実に約6倍の高速化です。
従来は年間でおよそ20時間近く待ち時間が発生していましたが、新しい方式では年間3時間ほどに短縮されました。
不具合などによりリカバーを行う場合や、はてなブログチームでは導入していませんが Site Reliability Engineering における error budget に対するインパクトも大きく変わりえます。
『継続的デリバリー』の p.68 より:
開発・テスト・リリースプロセスを自動化することで、ソフトウェアをリリースする際のスピードや品質、コストがかなりの影響を受ける。 ......それによってビジネス上の利益をより素早く提供できるようになる。リリースプロセス自体の敷居が下がっているからだ。
今回のデプロイ改善は直接利益をもたらすものではありませんが、リリースマスターの拘束時間が減ることにより心理的な負担が減るなど、はてなブログというサービスを改善し安定した提供を続けるためにポジティブな影響を与えています。
まとめ
はてなブログのデプロイを高速化した背景と導入のステップについて紹介しました。
この記事では紹介しませんでしたが、実際にデプロイを高速化したことで障害に繋がることを防げたこともあります。 エンジニア個人としても普段行うデプロイが速く済むのは数字以上に快適で達成感もありました。
この記事は、はてなエンジニアアドベントカレンダー2016の16日目の記事です。
昨日は ![]() id:amagitakayosi でした。明日は
id:amagitakayosi でした。明日は ![]() id:ikesyo です。
id:ikesyo です。









")
")


